이 섹션의 다중 페이지 출력 화면임. 여기를 클릭하여 프린트.
쿠버네티스 블로그
- 쿠버네티스 v1.34: 바람과 의지 (O' WaW)
- 쿠버네티스 1.24: gRPC 컨테이너 프로브 베타
- 쿠버네티스 1.22: 새로운 정점에 도달(Reaching New Peaks)
- 당황하지 마세요. 쿠버네티스와 도커
- 쿠버네티스에서 어려움 없이 gRPC 로드밸런싱하기
쿠버네티스 v1.34: 바람과 의지 (O' WaW)
편집자: Agustina Barbetta, Alejandro Josue Leon Bellido, Graziano Casto, Melony Qin, Dipesh Rawat
이전 릴리스와 마찬가지로 쿠버네티스 v1.34 릴리스에는 새로운 스테이블(Stable), 베타(Beta), 알파(Alpha) 기능이 포함되었습니다. 고품질의 릴리스가 지속적으로 제공되는 이유는 쿠버네티스 개발 주기의 강력함과 활발한 커뮤니티 덕분입니다.
이번 릴리스에는 58개의 개선 사항이 있습니다. 그 중 23개는 스테이블로 졸업하였으며, 22개는 베타로 진입, 13개는 알파에 진입하였습니다.
이번 릴리스에는 사용 중단 및 제거도 있으니 꼭 확인하시기 바랍니다.
릴리스 테마와 로고

우리 주변의 바람과 우리 내부 의지로 만들어진 릴리스입니다.
매 릴리스 주기마다 우리는 도구, 문서, 그리고 프로젝트의 역사적인 특이점과 같이 완전히 통제할 수 없는 바람을 맞습니다. 때로는 이 바람이 우리의 돛을 채우고, 때로는 옆으로 밀거나 잦아들기도 합니다.
쿠버네티스를 움직이는 것은 완벽한 바람이 아니라, 돛을 조정하고, 키를 잡고, 항로를 그리며 배를 안정적으로 유지하는 선원들의 의지입니다. 릴리스가 이루어지는 것은 항상 이상적인 조건이기 때문이 아니라, 그것을 만드는 사람들, 릴리스하는 사람들, 그리고 곰^, 고양이, 개, 마법사, 호기심 많은 이들이 어떤 바람이 불든 쿠버네티스를 힘차게 항해하게 하기 때문입니다.
이번 릴리스 바람과 의지 (O' WaW) 는 우리를 만든 바람과 앞으로 나아가게 하는 의지를 기립니다.
^ 아, 왜 곰일까요? 계속 궁금증을 가져보세요!
주요 업데이트 하이라이트
쿠버네티스 v1.34에는 새로운 기능과 개선 사항이 많습니다. 릴리스팀이 강조하고 싶은 주요 업데이트 몇 가지를 소개합니다.
스테이블: DRA의 핵심이 GA로
동적 리소스 할당 (DRA)는 GPU, TPU, NIC, 기타 장치를 더 강력하게 선택하고 할당하고 공유하고 구성할 수 있게 합니다.
v1.30 릴리스부터 DRA는 쿠버네티스의 코어에 영향을 주지 않는 방식으로(opaque)
*구조화된 매개변수(structured parameters)*로 장치를 클레임하는 방식으로 동작합니다. 이 개선 사항은
스토리지 볼륨의 동적 프로비저닝에서 영감을 받았습니다.
구조화된 매개변수를 사용하는 DRA는 ResourceClaim, DeviceClass,
ResourceClaimTemplate, ResourceSlice API 타입 등, 이를 지원하는 API kind를
기반으로 하고, 파드의 .spec에 새로운 resourceClaims 필드를 확장합니다.
resource.k8s.io/v1 API는 스테이블로 승격돼서 기본적으로 사용할 수 있습니다.
이 작업은 WG Device Management가 주도한 KEP #4381의 일환으로 진행되었습니다.
베타: kubelet 이미지 인증 제공자를 위한 프로젝티드 서비스어카운트(ServiceAccount) 토큰
kubelet의 이미지 인증 제공자는 프라이빗 컨테이너 이미지를 가져올 때, 전통적으로 노드나 클러스터에 저장된 장기 시크릿(Secret)에 의존했습니다. 이 방식은 인증 정보가 특정 워크로드에 연결되지 않고 자동으로 회전되지 않아서 보안 위험과 관리 부담이 컸습니다.
이 문제를 해결하기 위해, 이제 kubelet은 컨테이너 레지스트리 인증을 위해 단기적이고 오디언스(audience)가 지정된 서비스어카운트(ServiceAccount) 토큰을 요청할 수 있습니다. 그래서 이미지 풀 작업이 노드 수준 인증 정보가 아니라 파드의 고유한 신원에 기반해 승인이 이루어집니다.
주요 이점은 보안성이 크게 좋아진다는 것입니다. 이미지 풀을 위한 장기 시크릿이 필요 없어서 공격 표면이 줄고, 관리자와 개발자 모두 인증 정보 관리가 쉬워집니다.
이 작업은 SIG Auth와 SIG Node가 주도한 KEP #4412의 일환으로 진행되었습니다.
알파: KYAML(쿠버네티스에 최적화된 YAML 형식) 지원
KYAML은 쿠버네티스에 최적화되어 더 안전하고 모호함이 적은 YAML 하위 집합을 목표로 합니다. 어떤 버전의 쿠버네티스를 사용하든 쿠버네티스 v1.34부터는 kubectl의 새로운 출력 형식으로 KYAML을 사용할 수 있습니다.
KYAML은 YAML과 JSON 모두에 있는 특정 문제를 해결합니다. YAML은 공백이 중요해서 들여쓰기와 중첩에 신경 써야 하고, 문자열 인용이 선택적이라 예기치 않은 타입 변환이 생길 수 있습니다(예: "The Norway Bug"). 반면 JSON은 주석 지원이 없고, 끝에 쉼표와 키 인용에 엄격한 요구사항이 있습니다.
KYAML로 작성한 파일은 모든 버전의 kubectl에 입력으로 전달할 수 있고, KYAML 파일은 YAML로도 유효합니다. kubectl v1.34에서는 환경 변수 KUBECTL_KYAML=true를 설정하면 KYAML 출력을 요청할 수 있습니다(kubectl get -o kyaml …). 필요에 따라 기존 JSON 또는 YAML 형식도 계속 사용할 수 있습니다.
이 작업은 SIG CLI가 주도한 KEP #5295의 일환으로 진행되었습니다.
스테이블로 승격된 기능들
v1.34 릴리스에서 스테이블로 바뀐 주요 개선 사항 일부를 소개합니다.
잡의 대체 파드 지연 생성
기본적으로 잡 컨트롤러는 파드가 종료되기 시작하면 즉시 대체 파드를 생성해서 두 파드가 동시에 실행됩니다. 이는 리소스가 제한된 클러스터에서 대체 파드가 원래 파드가 완전히 종료될 때까지 사용 가능한 노드를 찾기 어려워져 리소스 경쟁을 유발할 수 있습니다. 또한, 이 상황은 원치 않는 클러스터 오토스케일러의 확장도 유발할 수 있습니다.
추가적으로, TensorFlow, JAX와 같은 일부 머신러닝 프레임워크는 한 번에 인덱스당 하나의 파드만 실행되어야 하므로 동시 실행이 문제가 될 수 있습니다.
이 기능은 잡에 .spec.podReplacementPolicy를 도입합니다. 파드가 완전히 종료(즉, .status.phase: Failed)된 경우에만 대체 파드를 생성하도록 선택할 수 있습니다. 이를 위해 .spec.podReplacementPolicy: Failed로 설정합니다.
v1.28에서 알파로 도입된 이 기능은 v1.34에서 스테이블로 승격되었습니다.
이 작업은 SIG Apps가 주도한 KEP #3939의 일환으로 진행되었습니다.
볼륨 확장 실패 복구
이 기능은 사용자가 기본 스토리지 제공자가 지원하지 않는 볼륨 확장을 취소하고, 더 작은 값으로 재시도할 수 있도록 합니다. v1.23에서 알파로 도입된 이 기능은 v1.34에서 스테이블로 승격되었습니다.
이 작업은 SIG Storage가 주도한 KEP #1790의 일환으로 진행되었습니다.
볼륨 수정용 VolumeAttributesClass
VolumeAttributesClass가 v1.34에서 스테이블로 승격되었습니다. VolumeAttributesClass는 프로비저닝된 IO 등 볼륨 매개변수를 수정할 수 있는 범용 쿠버네티스 네이티브 API입니다. 제공자가 지원하는 경우, 워크로드가 비용과 성능 균형을 위해 볼륨을 온라인으로 수직 확장할 수 있습니다. 쿠버네티스의 모든 새로운 볼륨 기능과 마찬가지로, 이 API는 컨테이너 스토리지 인터페이스(CSI)를 통해 구현됩니다. 프로비저너별 CSI 드라이버가 이 기능의 CSI 측면인 ModifyVolume API를 지원해야 합니다.
이 작업은 SIG Storage가 주도한 KEP #3751의 일환으로 진행되었습니다.
구조화된 인증 구성
쿠버네티스 v1.29는 API 서버 클라이언트 인증을 관리하기 위한 구성 파일 형식을 도입해서, 이전의 많은 커맨드라인 옵션 의존에서 벗어납니다. AuthenticationConfiguration 유형을 통해 관리자는 여러 JWT 인증자, CEL 표현식 검증, 동적 재로딩을 지원할 수 있습니다. 이 변화는 클러스터 인증 설정의 관리성과 감사 용이성(auditability)을 크게 향상시키며, v1.34에서 스테이블로 승격되었습니다.
이 작업은 SIG Auth가 주도한 KEP #3331의 일환으로 진행되었습니다.
셀렉터 기반 세분화된 권한 부여
쿠버네티스 권한 부여자(웹훅 인증자, 내장 노드 인증자 등)는 이제 들어오는 요청의 필드 및 레이블 셀렉터를 기반으로 권한 부여 결정을 내릴 수 있습니다. list, watch, deletecollection 요청에 셀렉터가 포함되면, 권한 부여 계층이 그 추가 컨텍스트로 접근을 평가할 수 있습니다.
예를 들어, 특정 .spec.nodeName에 바인딩된 파드만 나열할 수 있도록 권한 정책을 작성할 수 있습니다.
클라이언트(예: 특정 노드의 kubelet)는 정책이 요구하는
필드 셀렉터를 반드시 지정해야 하며, 그렇지 않으면 요청이 거부됩니다.
이 변경으로 클라이언트가 제한에 맞게 동작할 수 있다면 최소 권한 규칙을 설정하는 것이 가능해집니다.
쿠버네티스 v1.34는 노드별 격리, 커스텀 멀티테넌트 환경 등에서 더 세분화된 제어를 지원합니다.
이 작업은 SIG Auth가 주도한 KEP #4601의 일환으로 진행되었습니다.
세분화된 제어로 익명 요청 제한
익명 접근을 완전히 허용하거나 비활성화하는 대신, 이제 인증되지 않은 요청을 허용할 엔드포인트 목록을 엄격하게 지정할 수 있습니다. 이는 /healthz, /readyz, /livez와 같은 헬스 체크나 부트스트랩 엔드포인트에 익명 접근이 필요한 클러스터에 더 안전한 대안을 제공합니다.
이 기능을 통해 익명 사용자에게 광범위한 접근 권한을 부여하는 실수(RBAC 오동작)를 방지할 수 있고, 외부 프로브나 부트스트랩 도구를 변경할 필요가 없습니다.
이 작업은 SIG Auth가 주도한 KEP #4633의 일환으로 진행되었습니다.
플러그인별 콜백을 통한 더 효율적인 재큐잉(requeueing)
kube-scheduler에서는 이제 이전에 스케줄링할 수 없었던 파드를 다시 스케줄링하는 시점을 보다 정확하게 판단할 수 있습니다. 각 스케줄링 플러그인은 이제 콜백 함수를 등록해서, 클러스터 이벤트가 거부된 파드를 다시 스케줄링 가능하게 만들지 여부를 스케줄러에 알릴 수 있습니다.
이로 인해 불필요한 재시도 횟수가 줄고, 전체 스케줄링 처리량이 향상됩니다. 특히 동적 리소스 할당을 사용하는 클러스터에서 효과적입니다. 또한, 특정 플러그인은 안전할 경우 일반적인 백오프 지연을 건너뛸 수 있어서, 특정 상황에서 스케줄링이 더 빨라집니다.
이 작업은 SIG Scheduling이 주도한 KEP #4247의 일환으로 진행되었습니다.
네임스페이스 삭제 순서 지정
반복적으로 무작위로 리소스를 삭제하다보면, 네트워크 정책이 삭제된 후에도 파드가 남아있는 등 보안 문제나 의도치 않은 동작이 발생할 수 있습니다. 이 개선 사항은 쿠버네티스 네임스페이스의 삭제 과정을 더 구조적으로 만들어, 논리적, 보안적 의존성을 존중하는 삭제 순서를 강제함으로써 파드가 다른 리소스들보다 먼저 삭제되는 것을 보장합니다. 이 기능은 쿠버네티스 v1.33에서 도입되어 v1.34에서 스테이블로 승격됐다. 이로 인해 비결정적 삭제로 인한 위험(예: CVE-2024-7598에서 설명된 취약점)이 완화되어 보안성과 신뢰성이 향상됩니다.
이 작업은 SIG API Machinery가 주도한 KEP #5080의 일환으로 진행되었습니다.
list 응답 스트리밍
쿠버네티스에서 대규모 list 응답을 처리하는 것이 이전에는 확장성에 큰 도전이었습니다. 클라이언트가 수천 개의 파드나 커스텀 리소스 등 방대한 목록을 요청하면, API 서버는 모든 객체를 하나의 큰 메모리 버퍼에 직렬화한 뒤 전송해야 했습니다. 이 과정은 메모리 부담을 초래하고, 성능 저하 및 클러스터 안정성 저하로 이어질 수 있었습니다. 이를 해결하기 위해 컬렉션(list 응답)에 대한 스트리밍 인코딩 메커니즘이 도입되었습니다. JSON 및 쿠버네티스 Protobuf 응답 형식에서는 이 스트리밍 메커니즘이 자동으로 활성화되며, 관련 기능 게이트는 스테이블입니다. 이 방식의 주요 이점은 API 서버에서 대규모 메모리 할당을 피할 수 있어, 메모리 사용량이 훨씬 작고 예측이 가능해진다는 점입니다. 결과적으로, 대규모 환경에서 빈번한 대량 리소스 목록 요청이 있을 때 클러스터의 복원력과 성능이 크게 향상됩니다.
이 작업은 SIG API Machinery가 주도한 KEP #5116의 일환으로 진행되었습니다.
견고한 watch 캐시 초기화
Watch 캐시는 kube-apiserver 내부의 캐싱 계층으로, etcd에 저장된 클러스터 상태를 최종 일관성있는 상태로 캐싱을 합니다. 과거에는 kube-apiserver가 시작될 때 watch 캐시가 아직 초기화되지 않았거나 재초기화가 필요할 때 문제가 발생할 수 있었습니다.
이 문제를 해결하기 위해 watch 캐시 초기화 과정이 실패에 더 견고하게 대응하도록 개선해서, 컨트롤 플레인 안정성이 향상되고 컨트롤러 및 클라이언트가 신뢰성 있게 watch를 설정할 수 있게 되었습니다. 이 개선 사항은 v1.31에서 베타로 도입되어, 이제 스테이블입니다.
이 작업은 SIG API Machinery와 SIG Scalability가 주도한 KEP #4568의 일환으로 진행되었습니다.
DNS 검색 경로 검증 완화
이전에는 쿠버네티스에서 파드의 DNS 검색 경로에 대한 엄격한 검증이 복잡하거나 레거시 네트워크 환경에서 통합에 어려움을 초래했습니다. 이로 인해 조직 인프라에 필요한 구성을 막아서, 관리자가 어려운 우회 방법을 써야 했습니다.
이를 해결하기 위해 v1.32에서 알파로 도입된 완화된 DNS 검증이 v1.34에서 스테이블로 승격되었습니다. 대표적인 사용 사례는 파드가 쿠버네티스 내부 서비스와 외부 도메인 모두와 통신해야 하는 경우입니다. 파드의 .spec.dnsConfig에 대한 searches 목록 첫 번째 항목에 점(.)을 설정하면, 시스템 리졸버가 외부 쿼리에 클러스터 내부 검색 도메인을 추가하지 않게 됩니다. 이로 인해 외부 호스트명에 대해 내부 DNS 서버로 불필요한 요청이 발생하지 않아 효율성이 향상되고, 잠재적 이름 확인 오류도 방지할 수 있습니다.
이 작업은 SIG Network가 주도한 KEP #4427의 일환으로 진행되었습니다.
윈도우(Windows) kube-proxy의 Direct Service Return(DSR) 지원
DSR은 로드 밸런서를 통해 라우팅된 반환 트래픽이 로드 밸런서를 우회해서 클라이언트에 직접 응답하도록 해서, 로드 밸런서의 부하를 줄이고 전체 지연 시간을 개선하는 성능 최적화 기능입니다. 윈도우의 DSR에 대한 자세한 내용은 Direct Server Return (DSR) in a nutshell을 참고합니다. v1.14에서 처음 도입된 이 기능은 v1.34에서 스테이블로 승격되었습니다.
이 작업은 SIG Windows가 주도한 KEP #5100의 일환으로 진행되었습니다.
컨테이너 라이프사이클 훅의 Sleep 액션
컨테이너의 PreStop 및 PostStart 라이프사이클 훅에 Sleep 액션이 도입되어, 점진적 종료 관리와 전체 컨테이너 라이프사이클 관리가 더 쉬워집니다.
Sleep 액션은 컨테이너가 시작 후 또는 종료 전 지정된 시간만큼 일시정지할 수 있게 합니다. 음수 또는 0의 sleep 시간은 즉시 반환되어 아무 동작도 하지 않습니다.
Sleep 액션은 쿠버네티스 v1.29에서 도입됐고, 제로값 지원은 v1.32에 추가되었습니다. 두 기능 모두 v1.34에서 스테이블로 승격되었습니다.
이 작업은 SIG Node가 주도한 KEP #3960 및 KEP #4818의 일환으로 진행되었습니다.
리눅스 노드 스왑 지원
역사적으로 쿠버네티스에서 스왑 지원이 없으면, 노드에 메모리 압박이 있을 때 프로세스가 갑자기 종료되어 워크로드가 불안정해질 수 있었습니다. 이는 대용량이지만 드물게 접근하는 메모리 풋프린트를 가진 애플리케이션에 특히 영향을 줬고, 더 점진적인 리소스 관리가 불가능해졌습니다.
이를 해결하기 위해 노드별로 설정 가능한 스왑 지원이 v1.22에서 도입되었습니다. 알파와 베타 단계를 거쳐 v1.34에서 스테이블로 승격되었습니다. 기본 모드인 LimitedSwap은 파드가 기존 메모리 한도 내에서 스왑을 사용할 수 있게 해서, 문제에 직접적인 해결책을 제공합니다. 기본적으로 kubelet은 NoSwap 모드로 설정되어 쿠버네티스 워크로드는 스왑을 사용할 수 없습니다.
이 기능은 워크로드 안정성을 향상시키고 자원 활용도를 더욱 효율적으로 만듭니다. 자원에 제약이 있는 환경에서 보다 다양한 어플리케이션을 지원할 수 있게 해주지만, 관리자는 반드시 스왑 사용에 의한 잠재적인 성능 영향을 고려해야 합니다.
이 작업은 SIG Node가 주도한 KEP #2400의 일환으로 진행되었습니다.
환경 변수에 특수 문자 허용
쿠버네티스의 환경 변수 검증 규칙이 완화되어, =를 제외한 거의 모든
출력 가능한 ASCII 문자를 변수명에 사용할 수 있게 됩니다.
이 변경은 .NET Core와 같이 :를 중첩 구성 키로 사용하는 프레임워크 등 변수명에 비표준 문자가 필요한 워크로드를 지원합니다.
완화된 검증은 파드 명세에 직접 정의된 환경 변수뿐만 아니라, ConfigMap 및
시크릿을 참조해서 envFrom으로 주입된 환경 변수에도 적용됩니다.
이 작업은 SIG Node가 주도한 KEP #4369의 일환으로 진행되었습니다.
테인트(Taint) 관리와 Node 라이프사이클 분리
기존에는 노드 상태(NotReady, Unreachable 등)에 따라 NoSchedule 및 NoExecute 테인트를 적용하는 TaintManager의 로직이 노드 라이프사이클 컨트롤러와 강하게 결합되어 있었습니다. 이로 인해 코드 유지보수와 테스트가 어려워지고, 테인트 기반 축출 메커니즘의 유연성이 제한되었습니다.
이번 KEP에서는 TaintManager를 쿠버네티스 컨트롤러 매니저 내 별도의 컨트롤러로 리팩터링하였습니다. 이는 내부 아키텍처 개선으로, 코드 모듈화와 유지보수성을 높입니다. 이 변경으로 테인트 기반 축출 로직을 독립적으로 테스트하고 발전시킬 수 있지만, 테인트 사용 방식에 있어 직접적인 사용자 영향은 없습니다.
이 작업은 SIG Scheduling과 SIG Node가 주도한 KEP #3902의 일환으로 진행되었습니다.
베타로 승격된 신규 기능
v1.34 릴리스에서 베타가 된 주요 개선 사항 일부를 소개합니다.
파드 단위 리소스 요청 및 제한
여러 컨테이너가 포함된 파드의 리소스 요구사항을 정의하는 것은 그동안 어려웠습니다. 요청과 제한을 컨테이너 단위로만 설정할 수 있었기 때문입니다. 이로 인해 개발자는 각 컨테이너에 리소스를 과다 할당하거나, 원하는 총 리소스를 세밀하게 나누어야 했고, 설정이 복잡해지고 리소스 할당이 비효율적이었습니다. 이를 간소화하기 위해 파드 단위로 리소스 요청과 제한을 지정할 수 있는 기능이 도입되었습니다. 이제 개발자는 파드의 전체의 리소스 예산을 정의하고, 해당 리소스가 구성 컨테이너 간에 공유가 이루어집니다. 이 기능은 v1.32에서 알파로 도입되어 v1.34에서 베타로 승격됐으며, HPA도 파드 단위 리소스 명세를 지원합니다.
주요 이점은 다중 컨테이너 파드의 리소스를 더 직관적이고 간단하게 관리할 수 있다는 점입니다. 모든 컨테이너가 사용하는 총 리소스가 파드에 정의된 한도를 초과하지 않도록 보장해서, 리소스 계획, 스케줄링 정확도, 클러스터 리소스 활용 효율이 향상됩니다.
이 작업은 SIG Scheduling과 SIG Autoscaling이 주도한 KEP #2837의 일환으로 진행되었습니다.
kubectl 사용자 환경설정용 .kuberc 파일
.kuberc 구성 파일을 통해 kubectl의 기본 옵션, 명령어 별칭 등 사용자 환경설정을 정의할 수 있습니다. kubeconfig 파일과 달리 .kuberc에는 클러스터 정보, 사용자명, 비밀번호가 포함되지 않습니다.
이 기능은 v1.33에서 알파로 도입되어 환경 변수 KUBECTL_KUBERC로 활성화를 하였으며, v1.34에서는 베타로 승격되어 디폴트로 활성화됩니다.
이 작업은 SIG CLI가 주도한 KEP #3104의 일환으로 진행되었습니다.
외부 ServiceAccount 토큰 서명
전통적으로 쿠버네티스에서는 ServiceAccount 토큰을 kube-apiserver 시작 시 디스크에서 로드한 정적 서명 키로 관리합니다. 이번 기능은 외부 프로세스 서명을 위한 ExternalJWTSigner gRPC 서비스를 도입해서, 쿠버네티스 배포판이 ServiceAccount 토큰 서명에 정적 디스크 기반 키 대신 외부 키 관리 솔루션(HSM, 클라우드 KMS 등)과 통합할 수 있게 지원합니다.
v1.32에서 알파로 도입된 이 외부 JWT 서명 기능은 v1.34에서 베타로 승격되어 디폴트로 활성화됩니다.
이 작업은 SIG Auth가 주도한 KEP #740의 일환으로 진행되었습니다.
베타 상태인 DRA 기능
안전한 리소스 모니터링을 위한 관리자 접근 권한
DRA는 ResourceClaims 또는 ResourceClaimTemplates의 adminAccess 필드를 통해 관리자가 이미 다른 사용자가 사용 중인 장치에 모니터링이나 진단 목적으로 접근할 수 있도록 제어된 관리 권한을 지원합니다. 이 특권을 가진(privileged) 모드는 resource.k8s.io/admin-access: "true" 레이블이 지정된 네임스페이스에서 해당 오브젝트를 생성할 권한이 있는 사용자에게만 제한되므로, 일반 워크로드에는 영향을 주지 않습니다. v1.34에서 베타로 승격된 이 기능은 네임스페이스 기반 권한 검사를 통해 워크로드 격리를 유지하면서 안전한 인트로스펙션 기능을 제공합니다.
이 작업은 WG Device Management와 SIG Auth가 주도한 KEP #5018의 일환으로 진행되었습니다.
ResourceClaims 및 ResourceClaimTemplates의 우선순위 대안
워크로드가 단일 고성능 GPU에서 가장 잘 동작할 수 있지만, 두 개의 중간급 GPU에서 실행할 수도 있습니다.
DRAPrioritizedList 기능 게이트(이제 디폴트로 활성화)로 ResourceClaims와 ResourceClaimTemplates에 firstAvailable라는 새로운 필드가 추가되었습니다. 이 필드는 요청을 여러 방식으로 만족시킬 수 있음을 순서대로 지정할 수 있으며, 특정 하드웨어가 없으면 아무 것도 할당하지 않을 수도 있습니다. 스케줄러는 목록의 대안을 순서대로 만족시키려고 시도하므로, 워크로드는 클러스터에서 사용 가능한 최상의 장치 세트를 할당받게 됩니다.
이 작업은 WG Device Management가 주도한 KEP #4816의 일환으로 진행되었습니다.
kubelet의 DRA 리소스 할당 보고
kubelet의 API가 DRA를 통해 할당된 파드 리소스를 보고하도록 업데이트 되었습니다. 이를 통해 노드 모니터링 에이전트가 노드의 파드에 할당된 DRA 리소스를 확인할 수 있습니다. 또한, 노드 컴포넌트가 PodResourcesAPI를 사용해서 DRA 정보를 활용해 새로운 기능이나 통합을 개발할 수 있습니다.
쿠버네티스 v1.34부터 이 기능은 디폴트로 활성화됩니다.
이 작업은 WG Device Management가 주도한 KEP #3695의 일환으로 진행되었습니다.
kube-scheduler 논블로킹 API 호출
kube-scheduler는 스케줄링 사이클 중 블로킹 API 호출을 하며, 이는 성능 병목 현상을 만들어냅니다. 이번 기능은 우선순위 큐 시스템과 요청 중복 제거를 통한 비동기 API 처리를 도입해서, 스케줄러가 API 작업이 백그라운드에서 완료되는 동안 파드 처리를 계속할 수 있게 합니다. 주요 이점은 스케줄링 지연 감소, API 지연 시 스케줄러 스레드 고갈 방지, 스케줄링 불가 파드의 즉시 재시도 가능성 등입니다. 구현은 하위 호환성을 유지하며, 대기 중인 API 작업 모니터링을 위한 메트릭도 추가합니다.
이 작업은 SIG Scheduling이 주도한 KEP #5229의 일환으로 진행되었습니다.
변형 어드미션 정책(Mutating admission policies)
MutatingAdmissionPolicies는 변형 어드미션 웹훅에 대한, 선언적 방식과, 인프로세스(in-process) 대안을 제공합니다. 이 기능은 CEL의 객체 인스턴스화 및 JSON Patch 전략, 그리고 서버 사이드 Apply의 병합 알고리즘을 결합합니다. 관리자가 API 서버에서 직접 변형 규칙을 정의할 수 있어서 어드미션 제어가 크게 단순화됩니다. v1.32에서 알파로 도입된 변형 어드미션 정책은 v1.34에서 베타로 승격되었습니다.
이 작업은 SIG API Machinery가 주도한 KEP #3962의 일환으로 진행되었습니다.
스냅샷 가능한 API 서버 캐시
kube-apiserver의 캐싱 메커니즘(watch 캐시)은 최신 상태 요청을 효율적으로 처리합니다. 하지만 이전 상태(예: 페이징, resourceVersion 지정)로 list 요청을 하면 캐시를 우회해서 etcd에서 직접 데이터를 가져오게 됩니다. 이 직접 접근은 성능 비용이 크고, 대용량 리소스의 경우 대량 데이터 전송으로 인한 메모리 부담으로 안정성 문제가 발생할 수 있습니다.
ListFromCacheSnapshot 기능 게이트가 디폴트로 활성화되면, kube-apiserver는 요청된 resourceVersion보다 오래된 스냅샷이 있으면 그 스냅샷에서 응답을 제공합니다. kube-apiserver는 시작 시 스냅샷이 없고, 각 watch 이벤트마다 새 스냅샷을 만들고, etcd가 compacted되거나 캐시에 75초보다 오래된 이벤트가 가득 차면 스냅샷을 삭제합니다. 제공된 resourceVersion이 없으면 서버는 etcd로 다시 되돌아옵니다.
이 작업은 SIG API Machinery가 주도한 KEP #4988의 일환으로 진행되었습니다.
쿠버네티스 네이티브 타입에 대한 선언적인 검증 도구
이전까지 쿠버네티스 내장 API의 검증 규칙은 모두 수작업으로 작성되어, 유지보수자가 규칙을 찾고 이해하고 개선하거나 테스트하기 어려웠습니다. API에 적용될 수 있는 모든 검증 규칙을 한 번에 찾는 방법이 없었습니다. _선언적 검증_은 쿠버네티스 유지보수자에게 API 개발, 유지보수, 리뷰를 쉽게 해주고, 더 나은 도구와 문서화를 위한 프로그래밍적 검사를 가능하게 해줍니다. 쿠버네티스 라이브러리를 사용해 자체 코드(예시: 컨트롤러)를 작성하는 사람은 복잡한 검증 함수 대신 IDL 태그로 새 필드를 쉽게 추가할 수 있습니다. 이 변경은 검증 보일러플레이트(boilerplate)를 자동화해서 API 생성 속도를 높이고, 버전 타입에서 검증을 수행해 더 적합한 오류 메시지를 제공합니다. 이 개선 사항은 v1.33에서 베타로 승격되어 v1.34에서도 베타로 유지되며, CEL 기반 검증 규칙을 네이티브 쿠버네티스 타입에 도입합니다. 타입 정의에 직접 더 세분화되고 선언적인 검증을 정의할 수 있어서 API 일관성과 개발자 경험이 향상됩니다.
이 작업은 SIG API Machinery가 주도한 KEP #5073의 일환으로 진행되었습니다.
list 요청용 스트리밍 인포머
스트리밍 인포머 기능은 v1.32부터 베타였고, v1.34에서 추가 개선이 이루어졌습니다. 이 기능은 list 요청이 etcd에서 페이징 결과를 조립하는 대신, API 서버의 watch 캐시에서 객체를 연속 스트림으로 반환할 수 있게 해줍니다. watch 작업과 동일한 메커니즘을 재사용함으로써, API 서버는 대용량 데이터셋을 안정적으로 메모리 사용량을 유지하며 처리할 수 있습니다.
이번 릴리스에서는 kube-apiserver와 kube-controller-manager가 디폴트로 새로운 WatchList 메커니즘을 활용합니다. kube-apiserver는 list 요청을 더 효율적으로 스트리밍하고, kube-controller-manager는 인포머를 더 메모리 효율적이고 예측 가능하게 사용할 수 있습니다. 이 개선으로 대규모 list 작업 시 메모리 압박이 줄고, 지속적인 부하에서도 신뢰성이 향상되어 list 스트리밍이 더 예측 가능하고 효율적이 됩니다.
이 작업은 SIG API Machinery와 SIG Scalability가 주도한 KEP #3157의 일환으로 진행되었습니다.
윈도우 노드의 점진적 노드 종료 처리
윈도우 노드의 kubelet이 시스템 종료 이벤트를 감지해서 실행 중인 파드의 점진적 종료를 시작할 수 있게 해줍니다. 이는 기존 리눅스의 동작을 반영한 것으로, 계획된 종료나 재시작 시 워크로드가 깔끔하게 종료되도록 돕습니다.
시스템이 종료를 시작하면, kubelet은 표준 종료 로직을 사용해서 라이프사이클 훅과 그레이스 기간을 준수해서 노드가 꺼지기 전에 파드가 종료될 시간을 제공합니다. 이 기능은 윈도우의 사전 종료 알림을 활용해 프로세스를 조정합니다. 이번 개선으로 유지보수, 재시작, 시스템 업데이트 시 워크로드 신뢰성이 향상됩니다. 현재 베타이며 디폴트로 활성화됩니다.
이 작업은 SIG Windows가 주도한 KEP #4802의 일환으로 진행되었습니다.
인플레이스 파드(In-place Pod) 리사이즈 개선
v1.33에서 베타로 승격되어 기본 활성화된 인플레이스 파드 리사이즈 기능이 v1.34에서 추가 개선되었습니다. 여기에는 메모리 사용량 감소 지원과 파드 단위 리소스 통합을 포함합니다.
이 기능은 v1.34에서도 베타로 유지됩니다. 자세한 사용법과 예시는 컨테이너에 할당된 CPU 및 메모리 리소스 리사이즈 문서를 참고합니다.
이 작업은 SIG Node와 SIG Autoscaling이 주도한 KEP #1287에서 진행되었습니다.
알파로 승격된 신규 기능
v1.34 릴리스에서 알파가 된 주요 개선 사항 일부를 소개합니다.
mTLS 인증을 위한 파드 인증서
클러스터 내 워크로드 인증, 특히 API 서버와의 통신은 주로 ServiceAccount 토큰에 의존해왔습니다. 효과적이나, 이 토큰은 mTLS(상호 TLS)에서 강력하고 검증 가능한 신원을 제공하기에 항상 이상적이지 않고, 인증서 기반 인증을 기대하는 외부 시스템과 통합시 어려움이 있습니다.
쿠버네티스 v1.34는 PodCertificateRequests를 통해 파드가 X.509 인증서를 획득할 수 있는 내장 메커니즘을 도입합니다. kubelet이 파드용 인증서를 요청·관리할 수 있고, 이를 통해 쿠버네티스 API 서버 및 기타 서비스에 mTLS로 인증할 수 있습니다.
주요 이점은 파드에 더 강력하고 유연한 신원 메커니즘을 제공한다는 점입니다. bearer 토큰에만 의존하지 않고, 표준 보안 관행에 맞는 mTLS 인증을 네이티브로 구현할 수 있어서, 인증서 기반 관찰·보안 도구와의 통합도 간소화됩니다.
이 작업은 SIG Auth가 주도한 KEP #4317의 일환으로 진행되었습니다.
"Restricted" 파드 보안 표준에서 원격 프로브 금지
프로브 및 라이프사이클 핸들러의 host 필드는 podIP가 아닌 다른 엔티티를 kubelet이 프로브하도록 지정할 수 있습니다.
하지만 이 필드는 임의의 값(보안에 민감한 외부 호스트, 노드의 localhost 등)으로 설정할 수 있어 오용 및 보안 우회 공격 경로가 될 수 있습니다.
쿠버네티스 v1.34에서는, 파드가
host 필드를 비워두거나 해당 종류의 프로브를 사용하지 않을 때만
Restricted
파드 보안 표준을 충족합니다.
파드 보안 어드미션 또는 서드파티 솔루션을 사용해서 파드가 이 표준을 준수하도록 강제할 수 있습니다.
보안 제어이므로, 선택한 강제 메커니즘의 한계와 동작을 문서에서 반드시 확인합니다.
이 작업은 SIG Auth가 주도한 KEP #4940의 일환으로 진행되었습니다.
파드 배치 의사 표현을 위한 .status.nominatedNodeName 사용
kube-scheduler가 파드를 노드에 바인딩하는 데 시간이 걸릴 때, 클러스터 오토스케일러가 파드가 특정 노드에 바인딩될 것임을 이해하지 못해 해당 노드를 미사용으로 간주하고 삭제할 수 있습니다.
이 문제를 해결하기 위해, kube-scheduler는 프리엠션 진행뿐 아니라 파드 배치 의사를 표현하기 위해 .status.nominatedNodeName을 사용할 수 있습니다. NominatedNodeNameForExpectation feature gate를 활성화하면, 스케줄러가 이 필드를 사용해서 파드가 바인딩될 노드를 표시합니다. 이를 통해 외부 컴포넌트가 내부 예약 정보를 활용해 더 나은 결정을 내릴 수 있습니다.
이 작업은 SIG Scheduling이 주도한 KEP #5278의 일환으로 진행되었습니다.
알파 상태인 DRA 기능
DRA 리소스 헬스 상태
파드가 장애가 있거나 일시적으로 비정상인 장치를 사용할 때 이를 파악하기 어려워, 파드 충돌 원인 분석이 어렵거나 불가능할 수 있습니다.
DRA의 리소스 헬스 상태 기능은 파드에 할당된 장치의 헬스 상태를 파드의 상태에 노출해서 관찰성을 높입니다. 이를 통해 비정상 장치로 인한 파드 문제의 원인을 쉽게 파악하고 적절히 대응할 수 있습니다.
이 기능을 사용하려면 ResourceHealthStatus 기능 게이트를 활성화하고, DRA 드라이버가 DRAResourceHealth gRPC 서비스를 구현해야 합니다.
이 작업은 WG Device Management가 주도한 KEP #4680의 일환으로 진행되었습니다.
확장 리소스 매핑
확장 리소스 매핑은 DRA의 표현력 있고 유연한 접근 방식에 대한 더 간단한 대안으로, 리소스 용량과 소비를 쉽게 기술할 수 있게 해줍니다. 이 기능을 통해 클러스터 관리자는 DRA로 관리되는 리소스를 확장 리소스로 광고할 수 있고, 애플리케이션 개발자와 운영자는 익숙한 컨테이너의 .spec.resources 문법을 그대로 사용해서 이를 소비할 수 있습니다.
이 기능을 통해 기존 워크로드도 별도의 수정 없이 DRA를 도입할 수 있어서, 애플리케이션 개발자와 클러스터 관리자의 DRA 전환이 간소화됩니다.
이 작업은 WG Device Management가 주도한 KEP #5004의 일환으로 진행되었습니다.
DRA 소비 가능 용량(DRA consumable capacity)
쿠버네티스 v1.33에서는 리소스 드라이버가 전체 장치가 아닌, 사용 가능한 장치의 슬라이스만 광고할 수 있도록 지원했습니다. 하지만 이 방식은 장치 드라이버가 사용자 수요에 따라 장치 리소스의 세밀하고 동적인 부분을 관리하거나, 스펙과 네임스페이스로 제한되는 ResourceClaims와 독립적으로 리소스를 공유해야 하는 시나리오를 처리할 수 없었습니다.
DRAConsumableCapacity 기능 게이트를 활성화하면
(v1.34에서 알파로 도입)
리소스 드라이버가 동일한 장치 또는 장치의 슬라이스를 여러 ResourceClaims 또는 여러 DeviceRequests에 걸쳐 공유할 수 있습니다.
이 기능은 스케줄러가 capacity 필드에 정의된 장치 리소스의
일부를 할당할 수 있도록 확장합니다.
DRA의 이 기능은 네임스페이스와 클레임 간 장치 공유를 개선해서 파드의 요구에 맞게 조정할 수 있습니다. 드라이버가 용량 제한을 강제할 수 있고, 스케줄링을 개선하며, 대역폭 인식 네트워킹이나 멀티테넌트 공유 등 새로운 사용 사례도 지원합니다.
이 작업은 WG Device Management가 주도한 KEP #5075의 일환으로 진행되었습니다.
장치 바인딩 조건
쿠버네티스 스케줄러는 파드가 필요한 외부 리소스(예: attachable 장치, FPGA 등)가 준비되었는지 확인될 때까지 노드에 바인딩을 지연시켜 신뢰성을 높입니다. 이 지연 메커니즘은 스케줄링 프레임워크의 PreBind 단계에 구현되어 있습니다. 이 단계에서 스케줄러는 모든 필요한 장치 조건이 충족되었는지 확인한 후 바인딩을 진행합니다. 이를 통해 외부 장치 컨트롤러와의 조율이 가능해져, 더 견고하고 예측 가능한 스케줄링이 가능합니다.
이 작업은 WG Device Management가 주도한 KEP #5007의 일환으로 진행되었습니다.
컨테이너 재시작 규칙
현재 파드 내 모든 컨테이너는 종료 또는 충돌 시 동일한 .spec.restartPolicy를 따릅니다. 하지만 여러 컨테이너가 있는 파드는 각 컨테이너마다 다른 재시작 요구가 있을 수 있습니다. 예를 들어, 초기화용 init 컨테이너는 실패 시 재시작하지 않는 것이 바람직할 수 있습니다. ML 연구 환경의 장기 학습 워크로드에서는, 재시작 가능한 종료 코드로 실패한 컨테이너는 파드를 재생성하지 않고 빠르게 인플레이스 재시작하는 것이 좋습니다.
쿠버네티스 v1.34는 ContainerRestartRules 기능 게이트를 도입합니다. 활성화하면 파드 내 각 컨테이너에 대해 restartPolicy를 지정할 수 있습니다. 또한, 마지막 종료 코드에 따라 restartPolicy를 오버라이드하는 restartPolicyRules 목록도 정의할 수 있습니다. 이를 통해 복잡한 시나리오에 맞는 세분화된 제어와 컴퓨트 리소스의 더 나은 활용이 가능합니다.
이 작업은 SIG Node가 주도한 KEP #5307의 일환으로 진행되었습니다.
런타임 생성 파일에서 환경 변수 로드
애플리케이션 개발자는 환경 변수 선언의 유연성을 오랫동안 요구해왔습니다. 기존에는 환경 변수를 API 서버에서 고정(static) 값, 컨피그맵(ConfigMap), 시크릿 등으로 선언할 수 있었습니다.
EnvFiles 기능 게이트를 통해 쿠버네티스 v1.34는 런타임에 환경 변수를 선언할 수 있는 기능을 도입합니다.
한 컨테이너(주로 init 컨테이너)가 변수를 생성해서 파일에 저장하면,
이후 컨테이너가 해당 파일에서 환경 변수를 로드해 시작할 수 있습니다.
이 방식은 대상 컨테이너의 entrypoint를 "감쌀" 필요 없이, 파드 내 컨테이너 오케스트레이션을
더 유연하게 할 수 있게 합니다.
이 기능은 특히 AI/ML 학습 워크로드에 유용하며, 학습 잡의 각 파드가 런타임에 정의된 값으로 초기화되어야 할 때 활용됩니다.
이 작업은 SIG Node가 주도한 KEP #5307의 일환으로 진행되었습니다.
v1.34에서의 승격, 사용 중단, 제거 사항
스테이블로 승격된 기능
아래는 스테이블로 승격된 모든 기능 목록입니다. 알파에서 베타로 승격된 기능 등 전체 업데이트 목록은 릴리스 노트를 참고하십시오.
이번 릴리스에서는 총 23개의 개선 사항이 스테이블로 승격되었습니다.
- 환경 변수에 거의 모든 출력 가능한 ASCII 문자 허용
- Job 컨트롤러에서 완전히 종료된 Pod 재생성 허용
- PreStop Hook의 Sleep 액션에 0값 허용
- API 서버 트레이싱
- AppArmor 지원
- 필드 및 레이블 셀렉터로 권한 부여
- 캐시에서 일관된 읽기
- TaintManager와 NodeLifecycleController 분리
- CRI에서 cgroup 드라이버 탐지
- DRA: 구조화된 매개변수
- PreStop Hook의 Sleep 액션 도입
- Kubelet OpenTelemetry 트레이싱
- 쿠버네티스 VolumeAttributesClass ModifyVolume
- 노드 메모리 스왑 지원
- 지정된 엔드포인트에만 익명 인증 허용
- 네임스페이스 삭제 순서 지정
- kube-scheduler의 플러그인별 콜백 함수로 정확한 재큐잉
- DNS 검색 문자열 검증 완화
- 견고한 Watchcache 초기화
- LIST 응답의 스트리밍 인코딩
- 구조화된 인증 구성
- 윈도우 kube-proxy에서 Direct Service Return(DSR) 및 오버레이 네트워킹 지원
- 볼륨 확장 실패 복구 지원
사용 중단 및 제거
쿠버네티스가 발전하고 성숙해지면서, 프로젝트의 건강을 위해 기능이 사용 중단되거나 제거되거나 더 나은 기능으로 대체될 수 있습니다. 자세한 내용은 쿠버네티스 사용 중단 및 제거 정책을 참고합니다. 쿠버네티스 v1.34에는 몇 가지 사용 중단 사항이 포함되어 있습니다.
수동 cgroup 드라이버 설정 사용 중단
역사적으로 올바른 cgroup 드라이버를 설정하는 것은 쿠버네티스 클러스터 사용자에게 복잡한 작업이었습니다.
쿠버네티스 v1.28에서는 kubelet이
CRI 구현에 쿼리해서 사용할 cgroup 드라이버를 자동으로 감지하는 방식을 추가하였습니다. 이 자동 감지는 이제
강력히 권장되며, v1.34에서 스테이블로 승격되었습니다.
만약 사용 중인 CRI 컨테이너 런타임이 필요한
cgroup 드라이버를 보고할 수 없다면,
런타임을 업그레이드하거나 변경해야 합니다.
kubelet 구성 파일의 cgroupDriver 설정은 이제 사용 중단되었습니다.
명령줄 옵션 --cgroup-driver도 이전에 사용 중단됐으며,
쿠버네티스는 구성 파일을 대신 사용할 것을 권장합니다.
구성 설정과 명령줄 옵션 모두 향후 릴리스에서 제거될 예정이며,
v1.36 이전에는 제거되지 않습니다.
이 작업은 SIG Node가 주도한 KEP #4033의 일환으로 진행되었습니다.
v1.36에서 containerd 1.x 쿠버네티스 지원 종료 예정
쿠버네티스 v1.34는 여전히 containerd 1.7 및 기타 LTS 릴리스를 지원하지만,
자동 cgroup 드라이버 감지 도입에 따라 쿠버네티스 SIG Node 커뮤니티는
containerd v1.X에 대한 최종 지원 일정을 공식적으로 합의했습니다.
containerd 1.7 EOL과 맞물려, v1.35가 마지막 지원 릴리스가 될 예정입니다.
containerd 1.X를 사용 중이라면 곧 2.0+로 전환하는 것을 고려해야 합니다.
kubelet_cri_losing_support 메트릭을 모니터링하여 클러스터 내 노드가 곧
지원이 중단될 containerd 버전을 사용 중인지 확인합니다.
이 작업은 SIG Node가 주도한 KEP #4033의 일환으로 진행되었습니다.
PreferClose 트래픽 분배 사용 중단
쿠버네티스 서비스의 spec.trafficDistribution 필드는 트래픽을 서비스 엔드포인트에 라우팅하는 방식을 지정할 수 있습니다.
KEP-3015는 PreferClose를 사용 중단하고, 두 가지 추가 값인 PreferSameZone과 PreferSameNode를 도입합니다. PreferSameZone은 기존 PreferClose의 의미를 명확히 하기 위한 별칭입니다. PreferSameNode는 가능할 경우 로컬 엔드포인트로 연결을 전달하고, 불가능할 경우 원격 엔드포인트로 다시 되돌아옵니다.
이 기능은 v1.33에서 PreferSameTrafficDistribution 기능 게이트로 도입됐으며, v1.34에서 베타로 승격되어 디폴트로 활성화됩니다.
이 작업은 SIG Network가 주도한 KEP #3015의 일환으로 진행되었습니다.
릴리스 노트
쿠버네티스 v1.34 릴리스의 전체 세부사항은 릴리스 노트에서 확인합니다.
다운로드 및 시작하기
쿠버네티스 v1.34는 GitHub 또는 쿠버네티스 다운로드 페이지에서 다운로드할 수 있습니다.
쿠버네티스를 시작하려면 인터랙티브 튜토리얼을 참고하거나, minikube로 로컬 쿠버네티스 클러스터를 실행합니다. kubeadm을 사용하면 v1.34를 손쉽게 설치할 수 있습니다.
릴리스 팀
쿠버네티스는 커뮤니티의 지원, 헌신, 그리고 노력 없이는 불가능합니다. 각 릴리스 팀은 커뮤니티 자원봉사자들로 구성되어, 모두가 의존하는 쿠버네티스 릴리스를 함께 만들어갑니다. 이는 코드부터 문서, 프로젝트 관리까지 커뮤니티 각 분야의 전문성이 필요합니다.
Rodolfo "Rodo" Martínez Vega와의 기억을 존경합니다. 기술과 커뮤니티 빌딩에 대한 열정으로 쿠버네티스 커뮤니티에 큰 흔적을 남긴 헌신적인 기여자를 기억합니다. Rodo는 v1.22-v1.23과 v1.25-v1.30를 포함한 여러 릴리스에서 쿠버네티스 릴리스 팀 구성원으로 활약하며 프로젝트의 성공과 안정성에 변함없는 헌신을 보여줬습니다. 릴리스 팀 활동 외에도, Rodo는 Cloud Native LATAM 커뮤니티 활성화에 깊이 관여하며 언어와 문화의 장벽을 허물었습니다. 쿠버네티스 스페인어 문서와 CNCF 용어집 작업을 통해 스페인어권 개발자들에게 지식을 더 쉽게 전달하는 데 헌신했습니다. Rodo의 유산은 그가 멘토링한 수많은 커뮤니티 구성원, 그가 기여한 릴리스, 그리고 그가 키운 LATAM 쿠버네티스 커뮤니티에 살아 있습니다.
쿠버네티스 v1.34 릴리스를 커뮤니티에 제공하기 위해 노력해준 릴리스 팀 전체에 감사드립니다. 릴리스 팀은 첫 참여자부터 여러 릴리스를 경험한 리더까지 다양하게 구성되어 있습니다. 특히 릴리스 리드 Vyom Yadav에게 성공적인 릴리스 사이클을 이끌고, 문제 해결에 직접 나서며, 커뮤니티에 에너지와 배려를 불어넣어준 점에 깊이 감사드립니다.
프로젝트 속도
CNCF K8s DevStats 프로젝트는 쿠버네티스와 다양한 서브 프로젝트의 개발 속도와 관련된 흥미로운 데이터를 집계합니다. 여기에는 개인별 기여, 참여 기업 수 등 생태계 발전에 투입된 노력의 깊이와 폭을 보여주는 지표가 포함됩니다.
v1.34 릴리스 사이클(2025년 5월 19일~8월 27일, 15주) 동안 쿠버네티스에는 106개 기업과 491명의 개인이 기여했습니다. 더 넓은 클라우드 네이티브 생태계에서는 370개 기업, 2,235명의 기여자가 활동했습니다.
여기서 "기여"란 커밋, 코드 리뷰, 댓글, 이슈 또는 PR 생성, PR 리뷰(블로그·문서 포함), 이슈·PR 댓글 등 모든 활동을 포함합니다.
기여에 관심이 있다면 시작하기 페이지를 방문합니다.
이 데이터의 출처:
이벤트 소식
다가오는 쿠버네티스 및 클라우드 네이티브 행사를 소개합니다. KubeCon + CloudNativeCon, KCD, 그리고 전 세계 주요 컨퍼런스 정보를 확인하고 커뮤니티와 함께하세요!
2025년 8월
- KCD - Kubernetes Community Days: 콜롬비아: 2025년 8월 28일 | 보고타, 콜롬비아
2025년 9월
- CloudCon 시드니: 2025년 9월 9~10일 | 시드니, 호주
- KCD - Kubernetes Community Days: 샌프란시스코 베이 에어리어: 2025년 9월 9일 | 샌프란시스코, 미국
- KCD - Kubernetes Community Days: 워싱턴 DC: 2025년 9월 16일 | 워싱턴 D.C., 미국
- KCD - Kubernetes Community Days: 소피아: 2025년 9월 18일 | 소피아, 불가리아
- KCD - Kubernetes Community Days: 엘살바도르: 2025년 9월 20일 | 산살바도르, 엘살바도르
2025년 10월
- KCD - Kubernetes Community Days: 바르샤바: 2025년 10월 9일 | 바르샤바, 폴란드
- KCD - Kubernetes Community Days: 에든버러: 2025년 10월 21일 | 에든버러, 영국
- KCD - Kubernetes Community Days: 스리랑카: 2025년 10월 26일 | 콜롬보, 스리랑카
2025년 11월
- KCD - Kubernetes Community Days: 포르투: 2025년 11월 3일 | 포르투, 포르투갈
- KubeCon + CloudNativeCon North America 2025: 2025년 11월 10~13일 | 애틀랜타, 미국
- KCD - Kubernetes Community Days: 항저우: 2025년 11월 14일 | 항저우, 중국
2025년 12월
- KCD - Kubernetes Community Days: 스위스 로망드: 2025년 12월 4일 | 제네바, 스위스
최신 행사 정보는 여기에서 확인합니다.
다가오는 릴리스 웨비나
쿠버네티스 v1.34 릴리스 팀 멤버들이 2025년 9월 24일(수) 오후 4시(UTC) 에 릴리스 주요 내용을 소개하는 웨비나를 진행합니다. 자세한 정보와 등록은 CNCF 온라인 프로그램의 행사 페이지에서 확인합니다.
참여 방법
쿠버네티스에 참여하는 가장 쉬운 방법은 관심 분야에 맞는 다양한 SIG(Special Interest Group)에 가입하는 것입니다. 커뮤니티에 알리고 싶은 내용이 있다면, 매주 열리는 커뮤니티 미팅과 아래 채널을 통해 의견을 공유합니다. 지속적인 피드백과 응원에 감사드립니다.
- 최신 소식을 Bluesky @Kubernetesio에서 확인합니다
- Discuss에서 커뮤니티 토론에 참여합니다
- Slack에서 커뮤니티와 소통합니다
- Stack Overflow에서 질문을 올리거나 답변합니다
- 여러분의 쿠버네티스 스토리를 공유합니다
- 블로그에서 쿠버네티스 최신 소식을 읽습니다
- 쿠버네티스 릴리스 팀에 대해 더 알아봅니다
쿠버네티스 1.24: gRPC 컨테이너 프로브 베타
쿠버네티스 1.24에서 gRPC 프로브 기능이 베타에 진입했으며 기본적으로 사용 가능하다. 이제 HTTP 엔드포인트를 노출하지 않고, gRPC 앱에 대한 스타트업(startup), 활성(liveness) 및 준비성(readiness) 프로브를 구성할 수 있으며, 실행 파일도 필요하지 않는다. 쿠버네티스는 기본적으로 gRPC를 통해 워크로드에 자체적으로(natively) 연결 가능하며, 상태를 쿼리할 수 있다.
약간의 히스토리
시스템이 워크로드의 앱이 정상인지, 정상적으로 시작되었는지, 트래픽을 수용할 수 있는지에 대해 관리하는 것은 유용하다. gRPC 지원이 추가되기 전에도, 쿠버네티스는 이미 컨테이너 이미지 내부에서 실행 파일을 실행하거나, HTTP 요청을 하거나, TCP 연결이 성공했는지 여부를 확인하여 상태를 확인할 수 있었다.
대부분의 앱은, 이러한 검사로 충분하다. 앱이 상태(또는 준비성) 확인을
위한 gRPC 엔드포인트를 제공하는 경우 exec 프로브를
gRPC 상태 확인에 사용하도록 쉽게 용도를 변경할 수 있다.
블로그 기사 쿠버네티스의 gRPC 서버 상태 확인에서, Ahmet Alp Balkan은 이를 수행하는 방법을 설명하였으며, 이는 지금도 여전히 작동하는 메커니즘이다.
이것을 활성화하기 위해 일반적으로 사용하는 도구는 2018년 8월 21일에 생성되었으며, 이 도구의 첫 릴리즈는 2018년 9월 19일에 나왔다.
gRPC 앱 상태 확인을 위한 이 접근 방식은 매우 인기있다. grpc_health_probe를 포함하고 있는 Dockerfile은 3,626개이며, (문서 작성 시점에)GitHub의 기본 검색으로 발견된 yaml 파일은 6,621개가 있다. 이것은 도구의 인기와 이를 기본적으로 지원해야 할 필요성을 잘 나타낸다.
쿠버네티스 v1.23은 gRPC를 사용하여 워크로드 상태를 쿼리하는 기본(native) 지원을 알파 수준의 구현으로 기본 지원으로 도입 및 소개했다. 알파 기능이었기 때문에 v1.23 릴리스에서는 기본적으로 비활성화되었다.
기능 사용
우리는 다른 프로브와 유사한 방식으로 gRPC 상태를 확인할 수 있도록 구축했으며, 쿠버네티스의 다른 프로브에 익숙하다면 사용하기 쉬울 것이라 믿는다.
자체적으로 지원되는 상태 프로브는 grpc_health_probe 실행 파일과 관련되어 있던 차선책에 비해 많은 이점이 있다.
기본 gRPC 지원을 사용하면 이미지에 10MB의 추가 실행 파일을 다운로드하여 저장할 필요가 없다.
Exec 프로브는 실행 파일을 실행하기 위해 새 프로세스를 인스턴스화해야 하므로 일반적으로 gRPC 호출보다 느리다.
또한 파드가 리소스 최대치로 실행 중이고 새 프로세스를 인스턴스화하는데 문제가 있는 경우에는 검사의 분별성을 낮추게 만든다.
그러나 여기에는 몇 가지 제약이 있다. 프로브용 클라이언트 인증서(certificate)를 구성하는 것이 어렵기 때문에, 클라이언트 인증(authentication)이 필요한 서비스는 지원하지 않는다. 기본 제공(built-in) 프로브도 서버 인증서를 확인하지 않고 관련 문제를 무시한다.
또한 기본 제공 검사는 특정 유형의 오류를 무시하도록 구성할 수 없으며 (grpc_health_probe는 다른 오류에 대해 다른 종료 코드를 반환함), 단일 프로브에서 여러 서비스 상태 검사를 실행하도록 "연계(chained)"할 수 없다.
그러나 이러한 모든 제한 사항은 gRPC에서 꽤 일반적이며 이에 대한 쉬운 해결 방법이 있다.
직접 해 보기
클러스터 수준의 설정
오늘 이 기능을 사용해 볼 수 있다. 기본 gRPC 프로브 사용을 시도하려면, GRPCContainerProbe 기능 게이트를 활성화하여 쿠버네티스 클러스터를 직접 가동한다. 가용한 도구가 많이 있다.
기능 게이트 GRPCContainerProbe는 1.24에서 기본적으로 활성화되어 있으므로, 많은 공급업체가 이 기능을 즉시 사용 가능하도록 제공할 것이다.
따라서 선택한 플랫폼에서 1.24 클러스터를 그냥 생성하면 된다. 일부 공급업체는 1.23 클러스터에서 알파 기능을 사용 할 수 있도록 허용한다.
예를 들어, 빠른 테스트를 위해 GKE에서 테스트 클러스터를 가동할 수 있다. (해당 문서 작성 시점 기준) 다른 공급업체도 유사한 기능을 가지고 있을 수 있다. 특히 쿠버네티스 1.24 릴리스 이후 이 블로그 게시물을 읽고 있는 경우에는 더욱 그렇다.
GKE에서 다음 명령어를 사용한다. (참고로 버전은 1.23이고 enable-kubernetes-alpha가 지정됨).
gcloud container clusters create test-grpc \
--enable-kubernetes-alpha \
--no-enable-autorepair \
--no-enable-autoupgrade \
--release-channel=rapid \
--cluster-version=1.23
또한 클러스터에 접근하기 위해서 kubectl을 구성할 필요가 있다.
gcloud container clusters get-credentials test-grpc
기능 사용해 보기
gRPC 프로브가 작동하는 방식을 테스트하기 위해 파드를 생성해 보겠다. 이 테스트에서는 agnhost 이미지를 사용한다.
이것은 모든 종류의 워크로드 테스트에 사용할 수 있도록, k8s가 유지 관리하는 이미지다.
예를 들어, 두 개의 포트를 노출하는 유용한 grpc-health-checking 모듈을 가지고 있다. 하나는 상태 확인 서비스를 제공하고 다른 하나는 make-serving 및 make-not-serving 명령에 반응하는 http 포트다.
다음은 파드 정의의 예시이다. 이 예시는 grpc-health-checking 모듈을 시작하고, 포트 5000 및 8080을 노출하며, gRPC 준비성 프로브를 구성한다.
---
apiVersion: v1
kind: Pod
metadata:
name: test-grpc
spec:
containers:
- name: agnhost
# 이미지가 변경됨 (기존에는 "k8s.gcr.io" 레지스트리를 사용)
image: registry.k8s.io/e2e-test-images/agnhost:2.35
command: ["/agnhost", "grpc-health-checking"]
ports:
- containerPort: 5000
- containerPort: 8080
readinessProbe:
grpc:
port: 5000
test.yaml이라는 파일이 있으면, 파드를 생성하고 상태를 확인할 수 있다. 파드는 아래 출력 스니펫(snippet)에 표시된 대로 준비(ready) 상태가 된다.
kubectl apply -f test.yaml
kubectl describe test-grpc
출력에는 다음과 같은 내용이 포함된다.
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
이제 상태 확인 엔드포인트 상태를 NOT_SERVING으로 변경해 보겠다. 파드의 http 포트를 호출하기 위해 포트 포워드를 생성한다.
kubectl port-forward test-grpc 8080:8080
명령을 호출하기 위해 curl을 사용할 수 있다 ...
curl http://localhost:8080/make-not-serving
... 그리고 몇 초 후에 포트 상태가 준비되지 않음으로 전환된다.
kubectl describe pod test-grpc
이제 다음과 같은 출력을 확인할 수 있을 것이다.
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
...
Warning Unhealthy 2s (x6 over 42s) kubelet Readiness probe failed: service unhealthy (responded with "NOT_SERVING")
다시 전환되면, 약 1초 후에 파드가 준비(ready) 상태로 돌아간다.
curl http://localhost:8080/make-serving
kubectl describe test-grpc
아래 출력은 파드가 다시 Ready 상태로 돌아갔다는 것을 나타낸다.
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
쿠버네티스에 내장된 이 새로운 gRPC 상태 프로브를 사용하면 별도의 exec 프로브를 사용하는 이전 접근 방식보다 gRPC를 통한 상태 확인을 훨씬 쉽게 구현할 수 있다. 더 자세한 내용 파악을 위해 공식 문서를 자세히 살펴보고, 기능이 GA로 승격되기 전에 피드백을 제공하길 바란다.
요약
쿠버네티스는 인기 있는 워크로드 오케스트레이션 플랫폼이며 피드백과 수요를 기반으로 기능을 추가한다. gRPC 프로브 지원과 같은 기능은 많은 앱 개발자의 삶을 더 쉽게 만들고 앱을 더 탄력적으로 만들 수 있는 마이너한 개선이다. 오늘 기능을 사용해보고 기능이 GA로 전환되기 전에 오늘 사용해 보고 피드백을 제공해보자.
쿠버네티스 1.22: 새로운 정점에 도달(Reaching New Peaks)
2021년의 두 번째 릴리스인 쿠버네티스 1.22 릴리스를 발표하게 되어 기쁘게 생각합니다!
이번 릴리스는 53개의 개선 사항(enhancement)으로 구성되어 있습니다. 13개의 개선 사항은 스테이블(stable)로 졸업하였으며(graduated), 24개의 개선 사항은 베타(beta)로 이동하였고, 16개는 알파(alpha)에 진입하였습니다. 또한, 3개의 기능(feature)을 더 이상 사용하지 않게 되었습니다(deprecated).
이번 해 4월에는 쿠버네티스 릴리스 케이던스(cadence)가 1년에 4회에서 3회로 공식적으로 변경되었습니다. 이번 릴리스가 해당 방식에 따라 긴 주기를 가진 첫 번째 릴리스입니다. 쿠버네티스 프로젝트가 성숙해짐에 따라, 사이클(cycle) 당 개선 사항도 늘어나고 있습니다. 이것은 기여자 커뮤니티 및 릴리스 엔지니어링 팀에게, 버전과 버전 사이에 더 많은 작업이 필요하다는 것을 의미합니다. 또한 점점 더 많은 기능을 포함하는 릴리스로 최신 상태를 유지하려는 최종-사용자 커뮤니티에도 부담을 줄 수 있습니다.
연간 4회에서 3회로의 릴리스 케이던스 변경을 통해 프로젝트의 다양한 측면(기여와 릴리스가 관리되는 방법, 업그레이드 및 최신 릴리스 유지에 대한 커뮤니티의 역량 등)에 대한 균형을 이루고자 하였습니다.
더 자세한 사항은 공식 블로그 포스트 쿠버네티스 릴리스 케이던스 변경: 알아두어야 할 사항에서 확인할 수 있습니다.
주요 주제
서버-사이드 어플라이(Server-side Apply)가 GA로 졸업
서버-사이드 어플라이는 쿠버네티스 API 서버에서 동작하는 신규 필드 오너십이며 오브젝트 병합 알고리즘입니다. 서버-사이드 어플라이는 사용자와 컨트롤러가 선언적인 구성을 통해서 자신의 리소스를 관리할 수 있도록 돕습니다. 이 기능은 단순히 fully specified intent를 전송하는 것만으로 자신의 오브젝트를 선언적으로 생성 또는 수정할 수 있도록 허용합니다. 몇 릴리스에 걸친 베타 과정 이후, 서버-사이드 어플라이는 이제 GA(generally available)가 되었습니다.
외부 크리덴셜 제공자가 이제 스테이블이 됨
쿠버네티스 클라이언트 크리덴셜 플러그인에 대한 지원은 1.11부터 베타였으나, 쿠버네티스 1.22 릴리스에서 스테이블로 졸업하였습니다. 해당 GA 기능 집합은 인터랙티브 로그인 플로우(interactive login flow)를 제공하는 플러그인에 대한 향상된 지원을 포함합니다. 또한, 많은 버그가 수정되었습니다. 플러그인 개발은 sample-exec-plugin을 통해 시작할 수 있습니다.
etcd 3.5.0으로 변경
쿠버네티스의 기본 백엔드 저장소인 etcd 3.5.0이 신규로 릴리스되었습니다. 신규 릴리스에는 보안, 성능, 모니터링, 개발자 경험 측면의 개선 사항이 포함되어 있습니다. 많은 버그가 수정되었으며 구조화된 로깅으로 마이그레이션(migration to structured logging) 및 빌트-인 로그 순환(built-in log rotation)과 같은 신규 중요 기능들도 일부 포함되었습니다. 해당 릴리스는 트래픽 부하에 대한 솔루션 구현을 위한 자세한 차기 로드맵도 제시하고 있습니다. 3.5.0 릴리스 발표에서 변경에 대한 자세한 항목을 확인할 수 있습니다.
메모리 리소스에 대한 서비스 품질(Quality of Service)
쿠버네티스는 원래 v1 cgroups API를 사용했습니다. 해당 디자인에 의해서, Pod에 대한 QoS 클래스는 CPU 리소스(예를 들면, cpu_shares)에만 적용되었습니다. 알파 기능으로, 쿠버네티스 v1.22에서는 메모리 할당(allocation)과 격리(isolation)를 제어하기 위한 cgroups v2 API를 사용할 수 있습니다. 이 기능은 메모리 리소스에 대한 컨텐션(contention)이 있을 때 워크로드와 노드의 가용성을 향상시키고, 컨테이너 라이프사이클에 대한 예측 가능성을 향상시킬 수 있도록 디자인되었습니다.
노드 시스템 스왑(swap) 지원
모든 시스템 관리자나 쿠버네티스 사용자는 쿠버네티스를 설정하거나 사용할 때 스왑 공간(space)을 비활성화해야 한다는 동일한 상황에 놓여 있었습니다. 쿠버네티스 1.22 릴리스에서는 노드의 스왑 메모리를 지원합니다(알파). 이 변경은 블록 스토리지의 일부를 추가적인 가상 메모리로 취급하도록, 관리자의 옵트인(opt in)을 받아서 리눅스 노드에 스왑을 구성합니다.
윈도우(Windows) 개선 사항 및 기능
SIG Windows는 계속해서 성장하는 개발자 커뮤니티를 지원하기 위해서 개발 환경을 릴리스하였습니다. 이 새로운 도구는 여러 CNI 제공자를 지원하며, 여러 플랫폼에서 구동할 수 있습니다. 윈도우 kubelet과 kube-proxy를 컴파일하고, 다른 쿠버네티스 컴포넌트와 함께 빌드될 수 있도록 하는 새로운 방법을 제공하여, 최신(bleeding-edge) 윈도우 기능을 스크래치(scratch)부터 실행할 수 있도록 지원합니다.
1.22 릴리스에서 윈도우 노드의 CSI 지원이 GA 상태가 되었습니다. 쿠버네티스 v1.22에서는 특권을 가진(privileged) 윈도우 컨테이너가 알파가 되었습니다. 윈도우 노드에서 CSI 스토리지를 사용하도록, 노드에서의 스토리지 작업에 대한 특권을 가진(privileged) CSIProxy가 CSI 노드 플러그인을 특권을 가지지 않은(unprivileged) 파드로 배치되도록 합니다.
기본(default) seccomp 프로파일
알파 기능인 기본 seccomp 프로파일이 신규 커맨드라인 플래그 및 설정과 함께 kubelet에 추가되었습니다. 이 신규 기능을 사용하면, Unconfined대신 RuntimeDefault seccomp 프로파일을 기본으로 사용하는 seccomp이 클러스터 전반에서 기본이 됩니다. 이는 쿠버네티스 디플로이먼트(Deployment)의 기본 보안을 강화합니다. 워크로드에 대한 보안이 기본으로 더 강화되었으므로, 이제 보안 관리자도 조금 더 안심하고 쉴 수 있습니다. 이 기능에 대한 자세한 사항은 공식적인 seccomp 튜토리얼을 참고하시기 바랍니다.
kubeadm을 통한 보안성이 더 높은 컨트롤 플레인
이 신규 알파 기능을 사용하면 kubeadm 컨트롤 플레인 컴포넌트들을 루트가 아닌(non-root) 사용자로 동작시킬 수 있습니다. 이것은 kubeadm에 오랫동안 요청되어 온 보안 조치 사항입니다. 이 기능을 사용하려면 kubeadm에 한정된 RootlessControlPlane 기능 게이트를 활성화해야 합니다. 이 알파 기능을 사용하여 클러스터를 배치하는 경우, 사용자의 컨트롤 플레인은 더 낮은 특권(privileges)을 가지고 동작하게 됩니다.
또한 쿠버네티스 1.22는 kubeadm의 신규 v1beta3 구성 API를 제공합니다. 이 버전에는 오랫동안 요청되어 온 몇 가지 기능들이 추가되었고, 기존의 일부 기능들은 사용 중단(deprecated)되었습니다. 이제 v1beta3 버전이 선호되는(preferred) API 버전입니다. 그러나, v1beta2 API도 여전히 사용 가능하며 아직 사용 중단(deprecated)되지 않았습니다.
주요 변경 사항
사용 중단된(deprecated) 일부 베타 APIs의 제거
GA 버전과 중복된 사용 중단(deprecated)된 여러 베타 API가 1.22에서 제거되었습니다. 기존의 모든 오브젝트는 스테이블 APIs를 통해 상호 작용할 수 있습니다. 이 제거에는 Ingress, IngressClass, Lease, APIService, ValidatingWebhookConfiguration, MutatingWebhookConfiguration, CustomResourceDefinition, TokenReview, SubjectAccessReview, CertificateSigningRequest API의 베타 버전이 포함되었습니다.
전체 항목은 사용 중단된 API에 대한 마이그레이션 지침과 블로그 포스트 1.22에서 쿠버네티스 API와 제거된 기능: 알아두어야 할 사항에서 확인 가능합니다.
임시(ephemeral) 컨테이너에 대한 API 변경 및 개선
1.22에서 임시 컨테이너를 생성하기 위한 API가 변경되었습니다. 임시 컨테이너 기능은 알파이며 기본적으로 비활성화되었습니다. 신규 API는 예전 API를 사용하려는 클라이언트에 대해 동작하지 않습니다.
스테이블 기능에 대해서, kubectl 도구는 쿠버네티스의 버전 차이(skew) 정책을 따릅니다. 그러나, kubectl v1.21 이하의 버전은 임시 컨테이너에 대한 신규 API를 지원하지 않습니다. 만약 kubectl debug를 사용하여 임시 컨테이너를 생성할 계획이 있고 클러스터에서 쿠버네티스 v1.22로 구동하고 있는 경우, kubectl v1.21 이하의 버전에서는 그렇게 할 수 없다는 것을 알아두어야 합니다. 따라서 만약 클러스터 버전을 혼합하여 kubectl debug를 사용하려면 kubectl를 1.22로 업데이트하길 바랍니다.
기타 업데이트
스테이블로 졸업
- 바운드 서비스 어카운트 토큰 볼륨(Bound Service Account Token Volumes)
- CSI 서비스 어카운트 토큰(CSI Service Account Token)
- 윈도우의 CSI 플러그인 지원
- 사용 중단된 API 사용에 대한 경고(warning) 메커니즘
- PodDisruptionBudget 축출(eviction)
주목할만한 기능 업데이트
- 파드시큐리티폴리시(PodSecurityPolicy)를 대체하기 위한 새로운 파드시큐리티(PodSecurity) 어드미션(admission) 알파 기능이 소개됨.
- 메모리 관리자(manager)가 베타가 됨.
- API 서버 트레이싱(tracing)을 활성화하는 새로운 알파 기능.
- kubeadm 설정(configuration) 포맷의 신규 v1beta3 버전.
- 퍼시스턴트볼륨(PersistentVolume)을 위한 Generic data populators를 알파로 활용 가능.
- 쿠버네티스 컨트롤 플레인이 이제 크론잡 v2 컨트롤러(CronJobs v2 controller)를 사용하게 됨.
- 알파 기능으로, 모든 쿠버네티스 노드 컴포넌트(kubelet, kube-proxy, 컨테이너 런타임을 포함)는 루트가 아닌 사용자로 동작시킬 수 있음.
릴리스 노트
1.22 릴리스의 자세한 전체 사항은 릴리스 노트에서 확인할 수 있습니다.
릴리스 위치
쿠버네티스 1.22는 여기에서 다운로드할 수 있고, GitHub 프로젝트에서도 찾을 수 있습니다.
쿠버네티스를 시작하는 데 도움이 되는 좋은 자료가 많이 있습니다. 쿠버네티스 사이트에서 상호 작용형 튜토리얼을 수행할 수도 있고, kind와 도커 컨테이너를 사용하여 로컬 클러스터를 사용자의 머신에서 구동해볼 수도 있습니다. 클러스터를 스크래치(scratch)부터 구축해보고 싶다면, Kelsey Hightower의 쿠버네티스 어렵게 익히기(the Hard Way) 튜토리얼을 확인해보시기 바랍니다.
릴리스 팀
이 릴리스는 쿠버네티스 릴리스에 포함되는 모든 기술 콘텐츠, 문서, 코드, 기타 구성 요소 등을 제공하기 위해 팀들로 모인 매우 헌신적인 개인 그룹에 의해 가능했습니다.
팀을 성공적인 릴리스로 이끈 릴리스 리드 Savitha Raghunathan에게 감사드리며, 릴리스 팀 이외에도 커뮤니티에 1.22 릴리스를 제공하기 위해 열심히 작업하고 지원한 모든 사람들에게 감사드립니다.
우리는 또한 이 자리를 빌려 올해 초에 생을 마감한 팀 멤버 Peeyush Gupta를 추모하고 싶습니다. Peeyush Gupta는 SIG ContribEx 및 쿠버네티스 릴리스 팀에 활발히 참여했으며, 최근에는 1.22 커뮤니케이션 리드를 역임하였습니다. 그의 기여와 노력은 앞으로도 커뮤니티에 지속적으로 영향을 줄 것입니다. 그에 대한 추억과 추모를 공유하기 위한 CNCF 추모 페이지가 생성되어 있습니다.
릴리스 로고

진행 중인 팬데믹, 자연재해 및 항상 존재하는 번아웃의 그림자 속에서도, 쿠버네티스 1.22 릴리스는 53개의 개선 사항을 제공하였습니다. 이것은 현재까지 가장 큰 릴리스입니다. 이 성과는 열심히 일하고 열정적인 릴리스 팀 구성원과 쿠버네티스 생태계의 대단한 기여자들 덕분에 달성할 수 있었습니다. 이 릴리스 로고는 새로운 마일스톤과 새로운 기록을 세우기 위한 리마인더입니다. 이 로고를 모든 릴리스 팀 구성원, 등산객, 별을 보는 사람들에게 바칩니다!
이 로고는 Boris Zotkin가 디자인하였습니다. Boris는 MathWorks에서 Mac/Linux 관리자 역할을 맡고 있습니다. 그는 인생에서의 소소한 재미를 즐기고 가족과 함께 시간을 보내는 것을 사랑합니다. 이 기술에 정통(tech-savvy)한 개인은 항상 도전을 준비하며 친구를 돕는 것에 행복을 느낍니다!
사용자 하이라이트
- 5월에 CNCF가 전 세계에 걸친 27 기관을 다양한 클라우드 네이티브 생태계의 신규 멤버로 받았습니다. 이 신규 멤버는 다가오는 KubeCon + CloudNativeCon NA in Los Angeles (October 12 – 15, 2021)를 포함한 CNCF 이벤트들에 참여할 것입니다.
- CNCF는 KubeCon + CloudNativeCon EU – Virtual 2021에서 Spotify에 최고 엔드 유저 상(Top End User Award)을 수여했습니다.
프로젝트 속도(Velocity)
CNCF K8s DevStats 프로젝트는 쿠버네티스와 다양한 서브-프로젝트에 대한 흥미로운 데이터를 수집하고 있습니다. 여기에는 개인 기여부터 기여하는 회사 수에 이르기까지 모든 것이 포함되며, 이 생태계를 발전시키는 데 필요한 노력의 깊이와 넓이를 보여줍니다.
우리는 15주(4월 26일에서 8월 4일) 간 진행된 v1.22 릴리스 주기에서, 1063개의 기업과 2054명의 개인의 기여를 보았습니다.
생태계 업데이트
- 세 번째 가상 이벤트인 KubeCon + CloudNativeCon Europe 2021이 5월에 열렸습니다. 모든 발표가 온디맨드로 확인 가능합니다.
- Spring Term LFX 프로그램이 28명의 성공적인 인턴을 배출한 최대 규모의 졸업반을 가졌습니다!
- CNCF가 연초에 클라우드 네이티브 커뮤니티와 함께 배우고, 성장하고, 협업하기를 원하는 전 세계 누구에게나 상호 작용형 미디어 경험을 제공하고자, Twitch에서 라이브스트리밍을 시작하였습니다.
이벤트 업데이트
- KubeCon + CloudNativeCon North America 2021가 October 12 – 15, 2021에 Los Angeles에서 열립니다! 컨퍼런스와 등록에 대한 더 자세한 정보는 이벤트 사이트에서 찾을 수 있습니다.
- 쿠버네티스 커뮤니티 Days가 Italy, UK, Washington DC에서 이벤트를 앞두고 있습니다.
다가오는 릴리스 웨비나
이번 릴리스에 대한 중요 기능뿐만 아니라 업그레이드 계획을 위해 필요한 사용 중지된 사항이나 제거에 대한 사항을 학습하고 싶다면, 2021년 10월 5일에 쿠버네티스 1.22 릴리스 팀 웨비나에 참여하세요. 더 자세한 정보와 등록에 대해서는 CNCF 온라인 프로그램 사이트의 이벤트 페이지를 확인하세요.
참여하기
만약 쿠버네티스 커뮤니티 기여에 관심이 있다면, 특별 관심 그룹(Special Interest Groups, SIGs)이 좋은 시작 지점이 될 수 있습니다. 그중 많은 SIG가 당신의 관심사와 일치될 수 있습니다! 만약 커뮤니티와 공유하고 싶은 것이 있다면, 주간 커뮤니티 미팅에 참석할 수 있습니다. 또한 다음 중 어떠한 채널이라도 활용할 수 있습니다.
- 쿠버네티스 기여자 웹사이트에서 기여에 대한 더 자세한 사항을 확인
- 최신 정보 업데이트를 위해 @Kubernetesio 트위터 팔로우
- 논의(discuss)에서 커뮤니티 논의에 참여
- 슬랙에서 커뮤니티에 참여
- 쿠버네티스 사용기 공유
- 쿠버네티스에서 일어나는 일에 대한 자세한 사항을 블로그를 통해 읽기
- 쿠버네티스 릴리스 팀에 대해 더 알아보기
당황하지 마세요. 쿠버네티스와 도커
업데이트: 쿠버네티스의 도커심을 통한 도커 지원이 제거되었습니다. 더 자세한 정보는 제거와 관련된 자주 묻는 질문을 참고하세요. 또는 지원 중단에 대한 GitHub 이슈에서 논의를 할 수도 있습니다.
쿠버네티스는 v1.20 이후 컨테이너 런타임으로서 도커를 사용 중단(deprecating)합니다.
당황할 필요는 없습니다. 말처럼 극적이진 않습니다.
요약하자면, 기본(underlying) 런타임 중 하나인 도커는 쿠버네티스의 컨테이너 런타임 인터페이스(CRI)를 사용하는 런타임으로써는 더 이상 사용되지 않습니다(deprecated). 도커가 생성한 이미지는 늘 그래왔듯이 모든 런타임을 통해 클러스터에서 계속 작동될 것입니다.
쿠버네티스의 엔드유저에게는 많은 변화가 없을 것입니다.
이 내용은 도커의 끝을 의미하지 않으며, 도커를 더 이상 개발 도구로 사용할 수 없다거나,
사용하면 안 된다는 의미도 아닙니다. 도커는 여전히 컨테이너를
빌드하는 데 유용한 도구이며, docker build 실행 결과로 만들어진 이미지도 여전히 쿠버네티스 클러스터에서 동작합니다.
AKS, EKS 또는 GKE와 같은 관리형 쿠버네티스 서비스를 사용하는 경우 쿠버네티스의 향후 버전에서 도커에 대한 지원이 없어지기 전에, 워커 노드가 지원되는 컨테이너 런타임을 사용하고 있는지 확인해야 합니다. 노드에 사용자 정의가 적용된 경우 사용자 환경 및 런타임 요구 사항에 따라 업데이트가 필요할 수도 있습니다. 서비스 공급자와 협업하여 적절한 업그레이드 테스트 및 계획을 확인하세요.
자체 클러스터를 운영하는 경우에도, 클러스터의 고장을 피하기 위해서
변경을 수행해야 합니다. v1.20에서는 도커에 대한 지원 중단 경고(deprecation warning)가 표시됩니다.
도커 런타임 지원이 쿠버네티스의 향후 릴리스(현재는 2021년 하반기의
1.22 릴리스로 계획됨)에서 제거되면 더 이상 지원되지
않으며, containerd 또는 CRI-O와 같은 다른 호환 컨테이너 런타임 중
하나로 전환해야 합니다. 선택한 런타임이 현재 사용 중인
도커 데몬 구성(예: 로깅)을 지원하는지 확인하세요.
많은 사람들이 걱정하는 이유는 무엇이며, 왜 이런 혼란이 야기되었나요?
우리는 여기서 두 가지 다른 환경에 대해 이야기하고 있는데, 이것이 혼란을 야기하고 있습니다. 쿠버네티스 클러스터 내부에는 컨테이너 이미지를 가져오고 실행하는 역할을 하는 컨테이너 런타임이라는 것이 있습니다. 도커를 컨테이너 런타임(다른 일반적인 옵션에는 containerd 및 CRI-O가 있음)으로 많이 선택하지만, 도커는 쿠버네티스 내부에 포함(embedded)되도록 설계되지 않았기에 문제를 유발합니다.
우리가 "도커"라고 부르는 것은 실제로는 하나가 아닙니다. 도커는 전체 기술 스택이고, 그 중 한 부분은 그 자체로서 고수준(high-level)의 컨테이너 런타임인 "containerd" 입니다. 도커는 개발을 하는 동안 사람이 정말 쉽게 상호 작용할 수 있도록 많은 UX 개선을 포함하므로 도커는 멋지고 유용합니다. 하지만, 쿠버네티스는 사람이 아니기 때문에 이런 UX 개선 사항들이 필요하지 않습니다.
이 인간 친화적인 추상화 계층의 결과로, 쿠버네티스 클러스터는 containerd가 정말 필요로 하는 것들을 확보하기 위해서 도커심(Dockershim)이라는 다른 도구를 사용해야 합니다. 이것은 좋지 않습니다. 왜냐하면, 이는 추가적인 유지 관리를 필요로 하고 오류의 가능성도 높이기 때문입니다. 여기서 실제로 일어나는 일은 도커심이 빠르면 v1.23 릴리스에 Kubelet에서 제거되어, 결과적으로 도커에 대한 컨테이너 런타임으로서의 지원이 제거된다는 것입니다. 여러분 스스로도 생각할 수 있을 것입니다. containerd가 도커 스택에 포함되어 있는 것이라면, 도커심이 쿠버네티스에 왜 필요할까요?
도커는 컨테이너 런타임 인터페이스인 CRI를 준수하지 않습니다. 만약 이를 준수했다면, 심(shim)이 필요하지 않았을 것입니다. 그러나 이건 세상의 종말이 아니며, 당황할 필요도 없습니다. 여러분은 단지 컨테이너 런타임을 도커에서 지원되는 다른 컨테이너 런타임으로 변경하기만 하면 됩니다.
참고할 사항 한 가지: 현재 클러스터 내 워크플로의 일부가 기본 도커 소켓
(/var/run/docker.sock)에 의존하고 있는 경우, 다른
런타임으로 전환하는 것은 해당 워크플로의 사용에 문제를 일으킵니다. 이 패턴은 종종
도커 내의 도커라고 합니다. 이런 특정 유스케이스에 대해서
kaniko,
img와
buildah
같은 것들을 포함해 많은 옵션들이 있습니다.
그렇지만, 이 변경이 개발자에게는 어떤 의미인가요? 여전히 Dockerfile을 작성나요? 여전히 도커로 빌드하나요?
이 변경 사항은 사람들(folks)이 보통 도커와 상호 작용하는 데 사용하는 것과는 다른 환경을 제시합니다. 개발에 사용하는 도커의 설치는 쿠버네티스 클러스터 내의 도커 런타임과 관련이 없습니다. 혼란스럽죠, 우리도 알고 있습니다. 개발자에게 도커는 이 변경 사항이 발표되기 전과 마찬가지로 여전히 유용합니다. 도커가 생성하는 이미지는 실제로는 도커에만 특정된 이미지가 아니라 OCI(Open Container Initiative) 이미지입니다. 모든 OCI 호환 이미지는 해당 이미지를 빌드하는 데 사용하는 도구에 관계없이 쿠버네티스에서 동일하게 보입니다. containerd와 CRI-O는 모두 해당 이미지를 가져와 실행하는 방법을 알고 있습니다. 이것이 컨테이너가 어떤 모습이어야 하는지에 대한 표준이 있는 이유입니다.
변경은 다가오고 있습니다. 이 변경이 일부 문제를 일으킬 수도 있지만, 치명적이지는 않으며, 일반적으로는 괜찮은 일입니다. 사용자가 쿠버네티스와 상호 작용하는 방식에 따라 이 변경은 아무런 의미가 없거나 약간의 작업만을 의미할 수 있습니다. 장기적으로는 일이 더 쉬워질 것입니다. 이것이 여전히 혼란스럽더라도 괜찮습니다. 이에 대해서 많은 일이 진행되고 있습니다. 쿠버네티스에는 변화되는 부분이 많이 있고, 이에 대해 100% 전문가는 없습니다. 경험 수준이나 복잡성에 관계없이 어떤 질문이든 하시기 바랍니다! 우리의 목표는 모든 사람이 다가오는 변경 사항에 대해 최대한 많은 교육을 받을 수 있도록 하는 것입니다. 이 글이 여러분이 가지는 대부분의 질문에 대한 답이 되었고, 불안을 약간은 진정시켰기를 바랍니다! ❤️
더 많은 답변을 찾고 계신가요? 함께 제공되는 도커심 제거 FAQ(2022년 2월에 갱신됨)를 확인하세요.
쿠버네티스에서 어려움 없이 gRPC 로드밸런싱하기
저자: William Morgan (Buoyant)
번역: 송원석 (쏘카), 김상홍 (국민대), 손석호 (ETRI)
다수의 새로운 gRPC 사용자는 쿠버네티스의 기본 로드 밸런싱이 종종 작동하지 않는 것에 놀란다. 예를 들어, 만약 단순한 gRPC Node.js 마이크로서비스 앱을 만들고 쿠버네티스에 배포하면 어떤 일이 생기는지 살펴보자.
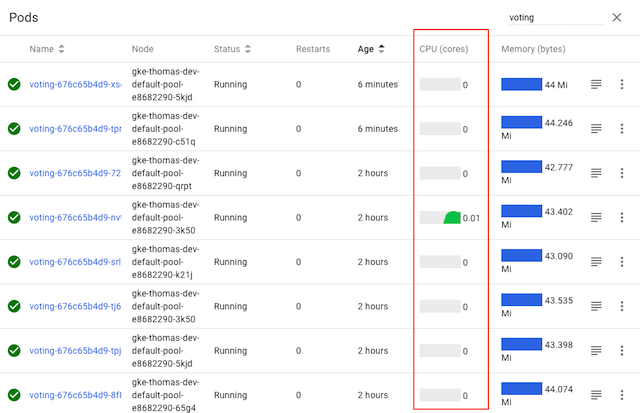
여기 표시된 voting 서비스는 여러 개의 파드로 구성되어 있지만, 쿠버네티스의 CPU 그래프는 명확하게
파드 중 하나만 실제 작업을 수행하고 있는 것(하나의 파드만 트래픽을 수신하고 있으므로)을
보여준다. 왜 그런 것일까?
이 블로그 게시물에서는, 이런 일이 발생하는 이유를 설명하고, CNCF의 서비스 메시(mesh)인 Linkerd 및 서비스 사이드카(sidecar)를 활용한 gRPC 로드밸런싱을 쿠버네티스 앱에 추가하여, 이 문제를 쉽게 해결할 수 있는 방법을 설명한다.
왜 gRPC에 특별한 로드밸런싱이 필요한가?
먼저, 왜 gRPC를 위해 특별한 작업이 필요한지 살펴보자.
gRPC는 애플리케이션 개발자에게 점점 더 일반적인 선택지가 되고 있다. JSON-over-HTTP와 같은 대체 프로토콜에 비해, gRPC는 극적으로 낮은 (역)직렬화 비용과, 자동 타입 체크, 공식화된 APIs, 적은 TCP 관리 오버헤드 등에 상당한 이점이 있다.
그러나, gRPC는 쿠버네티스에서 제공하는 것과 마찬가지로 표준(일반)적으로 사용되는 연결 수준 로드밸런싱(connection-level load balancing)을 어렵게 만드는 측면도 있다. gRPC는 HTTP/2로 구축되었고, HTTP/2는 하나의 오래 지속되는 TCP 연결을 갖도록 설계되있기 때문에, 모든 요청은 다중화(multiplexed)(특정 시점에 다수의 요청이 하나의 연결에서만 동작하는 것을 의미)된다. 일반적으로, 그것은 연결 관리 오버헤드를 줄이는 장점이 있다. 그러나, 그것은 또한 (상상할 수 있듯이) 연결 수준의 밸런싱(balancing)에는 유용하지 않다는 것을 의미한다. 일단 연결이 설정되면, 더 이상 밸런싱을 수행할 수 없기 때문이다. 모든 요청이 아래와 같이 단일 파드에 고정될 것이다.
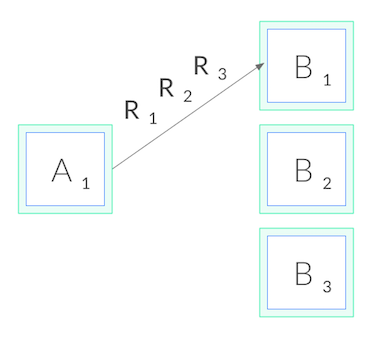
왜 HTTP/1.1에는 이러한 일이 발생하지 않는가?
HTTP/1.1 또한 수명이 긴 연결의 개념이 있지만, HTTP/1.1에는 TCP 연결을 순환시키게 만드는 여러 특징들이 있기 때문에, 이러한 문제가 발생하지 않는다. 그래서, 연결 수준 밸런싱은 "충분히 양호"하며, 대부분의 HTTP/1.1 앱에 대해서는 더 이상 아무것도 할 필요가 없다.
그 이유를 이해하기 위해, HTTP/1.1을 자세히 살펴보자. HTTP/2와 달리 HTTP/1.1은 요청을 다중화할 수 없다. TCP 연결 시점에 하나의 HTTP 요청만 활성화될 수 있다. 예를 들어 클라이언트가 'GET /foo'를 요청하고, 서버가 응답할 때까지 대기한다. 요청-응답 주기가 발생하면, 해당 연결에서 다른 요청을 실행할 수 없다.
일반적으로, 우리는 병렬로 많은 요청이 발생하기 원한다. 그러므로, HTTP/1.1 동시 요청을 위해, 여러 HTTP/1.1 연결을 만들어야 하고, 그 모두에 걸쳐 우리의 요청을 발행해야 한다. 또한, 수명이 긴 HTTP/1.1 연결은 일반적으로 일정 시간 후 만료되고 클라이언트(또는 서버)에 의해 끊어진다. 이 두 가지 요소를 결합하면 일반적으로 HTTP/1.1 요청이 여러 TCP 연결에서 순환하며, 연결 수준 밸런싱이 작동한다.
그래서 우리는 어떻게 gRPC의 부하를 분산할 수 있을까??
이제 gRPC로 돌아가보자. 연결 수준에서 밸런싱을 맞출 수 없기 때문에, gRPC 로드 밸런싱을 수행하려면, 연결 밸런싱에서 요청 밸런싱으로 전환해야 한다. 즉, 각각에 대한 HTTP/2 연결을 열어야 하고, 아래와 같이, 이러한 연결들로 요청의 밸런싱을 맞춘다.
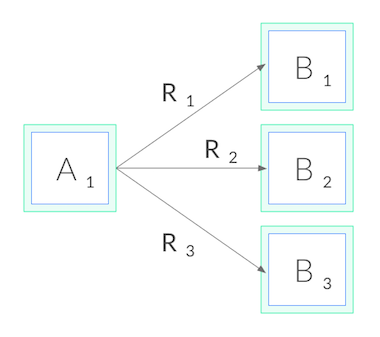
네트워크 측면에서, L3/L4에서 결정을 내리기 보다는 L5/L7에서 결정을 내려야 한다. 즉, TCP 연결을 통해 전송된 프로토콜을 이해해야 한다.
우리는 이것을 어떻게 달성해야할까? 몇 가지 옵션이 있다. 먼저, 우리의 애플리케이션 코드는 대상에 대한 자체 로드 밸런싱 풀을 수동으로 유지 관리할 수 있고, gRPC 클라이언트에 로드 밸런싱 풀을 사용하도록 구성할 수 있다. 이 접근 방식은 우리에게 높은 제어력을 제공하지만, 시간이 지남에 따라 파드가 리스케줄링(reschedule)되면서 풀이 변경되는 쿠버네티스와 같은 환경에서는 매우 복잡할 수 있다. 이 경우, 우리의 애플리케이션은 파드와 쿠버네티스 API를 관찰하고 자체적으로 최신 상태를 유지해야 한다.
대안으로, 쿠버네티스에서 앱을 헤드리스(headless) 서비스로 배포할 수 있다. 이 경우, 쿠버네티스는 서비스를 위한 DNS 항목에 다중 A 레코드를 생성할 것이다. 만약 충분히 진보한 gRPC 클라이언트를 사용한다면, 해당 DNS 항목에서 로드 밸런싱 풀을 자동으로 유지 관리할 수 있다. 그러나 이 접근 방식은 우리를 특정 gRPC 클라이언트로를 사용하도록 제한할 뿐만 아니라, 헤드리스 서비스만 사용하는 경우도 거의 없으므로 제약이 크다.
마지막으로, 세 번째 접근 방식을 취할 수 있다. 경량 프록시를 사용하는 것이다.
Linkerd를 사용하여 쿠버네티스에서 gRPC 로드 밸런싱
Linkerd는 CNCF에서 관리하는 쿠버네티스용 서비스 메시이다. 우리의 목적과 가장 관련이 깊은 Linkerd는, 클러스터 수준의 권한 없이도 단일 서비스에 적용할 수 있는 서비스 사이드카로써도 작동한다. Linkerd를 서비스에 추가하는 것은, 각 파드에 작고, 초고속인 프록시를 추가하는 것을 의미하며, 이러한 프록시가 쿠버네티스 API를 와치(watch)하고 gRPC 로드 밸런싱을 자동으로 수행하는 것을 의미이다. 우리가 수행한 배포는 다음과 같다.
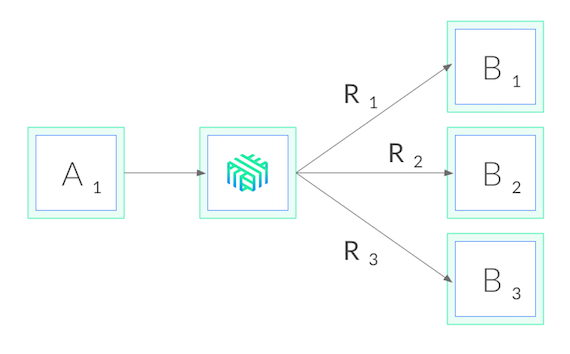
Linkerd를 사용하면 몇 가지 장점이 있다. 첫째, 어떠한 언어로 작성된 서비스든지, 어떤 gRPC 클라이언트든지 그리고 어떠한 배포 모델과도 (헤드리스 여부와 상관없이) 함께 작동한다. Linkerd의 프록시는 완전히 투명하기 때문에, HTTP/2와 HTTP/1.x를 자동으로 감지하고 L7 로드 밸런싱을 수행하며, 다른 모든 트래픽을 순수한 TCP로 통과(pass through)시킨다. 이것은 모든 것이 그냥 작동한다는 것을 의미한다.
둘째, Linkerd의 로드 밸런싱은 매우 정교하다. Linkerd는 쿠버네티스 API에 대한 와치(watch)를 유지하고 파드가 리스케술링 될 때 로드 밸런싱 풀을 자동으로 갱신할 뿐만 아니라, Linkerd는 응답 대기 시간이 가장 빠른 파드에 요청을 자동으로 보내기 위해 지수 가중 이동 평균(exponentially-weighted moving average) 을 사용한다. 하나의 파드가 잠시라도 느려지면, Linkerd가 트래픽을 변경할 것이다. 이를 통해 종단 간 지연 시간을 줄일 수 있다.
마지막으로, Linkerd의 Rust 기반 프록시는 매우 작고 빠르다. 그것은 1ms 미만의 p99 지연 시간(<1ms of p99 latency)을 지원할 뿐만 아니라, 파드당 10mb 미만의 RSS(<10mb of RSS)만 필요로 하므로 시스템 성능에도 거의 영향을 미치지 않는다.
60초 안에 gRPC 부하 분산
Linkerd는 시도하기가 매우 쉽다. 단지 —랩탑에 CLI를 설치하고— Linkerd 시작 지침의 단계만 따르면 된다. 클러스터에 컨트롤 플레인과 "메시" 서비스(프록시를 각 파드에 주입)를 설치한다. 서비스에 Linkerd가 즉시 실행될 것이므로 적절한 gRPC 밸런싱을 즉시 확인할 수 있다.
Linkerd 설치 후에, 예시 voting 서비스를
다시 살펴보자.
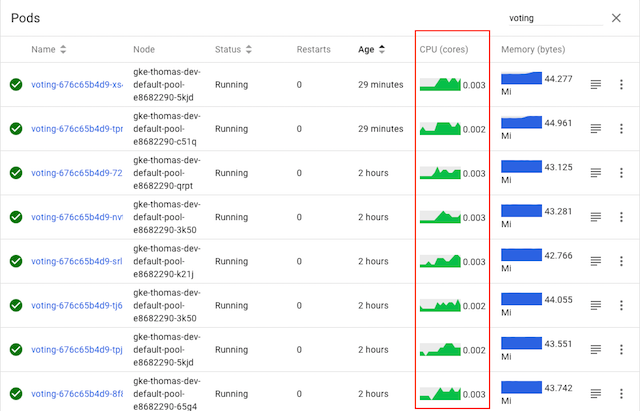
그림과 같이, 모든 파드에 대한 CPU 그래프가 활성화되어 모든 파드가 —코드를 변경하지 않았지만— 트래픽을 받고 있다. 짜잔, 마법처럼 gRPC 로드 밸런싱이 됐다!
Linkerd는 또한 내장된 트래픽 수준 대시보드를 제공하므로, 더 이상 CPU 차트에서 무슨 일이 일어나고 있는지 추측하는 것이 필요하지 않다. 다음은 각 파드의 성공률, 요청 볼륨 및 지연 시간 백분위수를 보여주는 Linkerd 그래프이다.
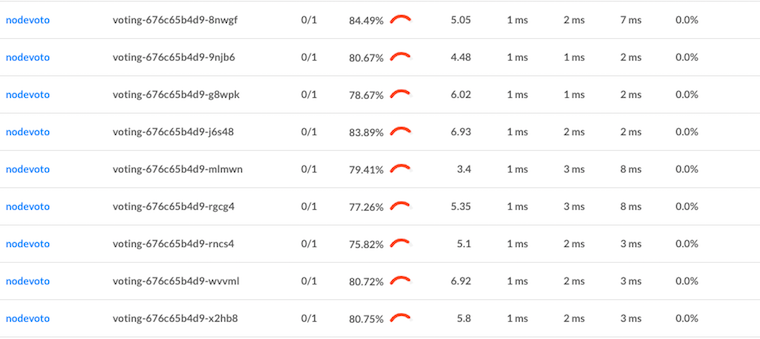
각 파드가 약 5 RPS를 얻고 있음을 알 수 있다. 또한, 로드 밸런싱 문제는 해결되었지만 해당 서비스의 성공률에 대해서는 아직 할 일이 남았다는 것도 살펴볼 수 있다. (데모 앱은 독자에 대한 연습을 위해 의도적으로 실패 상태로 만들었다. Linkerd 대시보드를 사용하여 문제를 해결할 수 있는지 살펴보자!)
마지막으로
쿠버네티스 서비스에 gRPC 로드 밸런싱을 추가하는 방법에 흥미가 있다면, 어떤 언어로 작성되었든 상관없이, 어떤 gRPC 클라이언트를 사용중이든지, 또는 어떻게 배포되었든지, Linkerd를 사용하여 단 몇 개의 명령으로 gRPC 로드 밸런싱을 추가할 수 있다.
보안, 안정성 및 디버깅을 포함하여 Linkerd에는 더 많은 특징 및 진단 기능이 있지만 이는 향후 블로그 게시물의 주제로 남겨두려 한다.
더 알고 싶은가? 빠르게 성장하고 있는 우리 커뮤니티는 여러분의 참여를 환영한다! Linkerd는 CNCF 프로젝트로 GitHub에 호스팅 되어 있고, Slack, Twitter, 그리고 이메일 리스트를 통해 커뮤니티를 만날 수 있다. 접속하여 커뮤니티에 참여하는 즐거움을 느껴보길 바란다!